
15 Free Full-Text Search Engine Solutions for developers

Hazem Abbas

Full-Text Search is a technical term referred to advanced linguistic text query for a database or text documents. The search engine examines all the words stored in a document as it tries to match certain search criteria giving by the user. Many web websites depend on Full-text search to perform advanced search operations. As a new trend, many developers, and companies tend to create static websites instead of dynamic database-driven ones. In both cases they can use Full-Text search with help of several libraries and services.
Some cloud-based services offer Full-Text search as a service like Algolia.com . However, open-source alternatives can save time and resources as provide better control for enterprise.
Why is Full-text search required?
- Speed: Using Full-text search ensure speed in retrieval of the results for large numbers of documents of a huge text database.
- Efficiency: Accurate precise search results in all fields.
- Configurable search criteria and logic.
- Static websites support: Many static websites use flat-files approach like JSON or Markdown formatted files. Some libraries and frameworks are using
- Mobile apps support
Implementing Full-text search with static generated websites is a necessity, especially when most of the static website generators don't include search as a primary functionality. Also, if you are using a self-hosted Ghost blog system, you may want to include a full-text search yourself, mainly because Ghost does not offer built-in search.
Here we will list the best open-source full-text search libraries for developers which can be used to enrich the user experience and provide more valid and accurate search results.
LunrJS is a JavaScript library designed to work on the browser and the server. It does not require any external dependencies or any extra service. It comes with multiple languages processors which can be tweaked according to the user needs.
It's a lightweight alternative library for Apache Solr. Lunr supports 14 languages out-of-box and offers fuzzy term.
2- Apache Solr
As an enterprise-grade platform, Solr is packed with features like load-balancing queries, automated functions, centralized configuration, distributed instant indexing and scale-ready infrastructure. Solr is used by several big players like DuckDuckGo, AT&T, Instagram, eBey, Comcast, Magento eCommerce, Adobe, Netflix, Internet Archive and more.
Developer can build apps on Solr easily because it supports many open-standards interfaces: JSON, XML and HTTP.

3- Sphinx Search
Sphinx is a full-text search engine server written in C++ for best performance. It works seamlessly on Windows, Linux, macOS. It indexes all data in SQL or NoSQL database. Sphinx offers a rich API (SphinxAPI) that allows developer to integrate it easily and search using SphinxQL which resample old school SQL.
It's proven to index 10-15mb of text per second per single CPU core and 60+MB/sec per server. For a double core desktop machine it runs 500+ queries/sec.
Sphinx is a scale ready, it's noted that the biggest Sphinx cluster indexes 25+ billion documents at Craigslist serving 300+ million search queries/day.
It features, SQL/ NoSQL database indexing, non-text attributes search, real-time full-text indexing and supports distributed search.
4- Manticore Search
Manticore Search is a multilingual full-text search with support for big data sets and real-time data streaming.
It's the best project on this list that offers unique features as geo-search, replications, search ranking algorithms, real-time indexing and built-in JSON support. Manticore search provide indexing support for MySQL, PostgreSQL, and flat files like CSV, TSV as well as markdown files. It also has a built-in morphology support for many languages.

5- Apache Lucene Core
Apache Lucene is a full-featured text search engine library. It's highly scalable with real-time text indexing and low hardware requirements.
Its features include: search ranked (favoring best results), dozens of search query types, field search, multiple indexing strategies, multiple ranking models and configurable storage engines.
Apache Lucense is built with Java, so it works on all known systems with implementations in other languages (C++, .NET, PHP5, Perl, Lisp, Python, Delphi, Objective-C, and Ruby).

6- Ambar Cloud
Ambar Cloud is an open-source document search engine with automated crawling, OCR, tagging and real-time indexing.
It supports all known text document format. It also performs automated OCR on images and PDF files.

7- Elasticlunr.js
Elasticlunr.js is a lightweight full-text search engine built with JavaScript for browser and server. It's supports query-time boosting field search and Boolean model queries.
It does not require deployment and offers an offline search functionalities.
It works with browser either desktop or mobile. It also works seamlessly with mobile applications that built with Cordova and JavaScript hybrid frameworks.
8- Apache Nutch
Apache Nutch is a highly extensible and scalable open-source crawler, text-indexer and full-text search engine.
9- Typesense
Typesense is a free open-source search engine with user and developer-friendly functionalities. It supports full-text search, automatic suggest, ranking results, allows a wide range of filters and facets, and it's also a typo tolerant.

10- Groonga
Yet another full-text open-source search engine and a column database for enterprise. It's fast, supports aggregated queries and inverted index.
It's the second solution on this list that supports Geo-location search out-of-box.
Groonga is built with pure C language, and it has libraries for many other popular languages like Ruby, Python and .Net.

Bleve is a full-text search engine written in Go language. It's simple, fast and lightweight. It supports text analysis out of box and many languages like French, Dutch, Turkish, Italian, Persian, Arabic, Russian and many more.

12- HubbleDotNet
HubbleDotNet is .Net based full-text search engine. It acts as a full-text search library for .Net projects. It fast and it comes with SQL support. Please note that HubbleDotNet didn't receive any update for years.
13- TNTSearch
A full-text search engine written completely in PHP. It features fuzzy search, Geo-search, text classification, Boolean search, result highlighting and dynamic indexing.
TNTSearch supports many languages as: English, German, French, Dutch, Russian, Italian. It also provides a full support for RT languages like Arabic, Hebrew and Persian.
14- Flex Search (FlexSearch)
Flex Search is a Node.JS-based full-text search library for JavaScript server and browser applications. It's fast, lightweight and easy to implement in Node.js apps.
MG4J is a cross-platform full-text search engine for text documents. It has advanced customizable indexing tool with support for multi-index interval semantics. It supports virtual fields, distributed search, multi-threading and clustering.
Bayard is a full-text search engine and indexing server built with Rust language on top of Tantivy a full-text search engine (Rust). It features index replication, clustering and comes with command-line interface. It's under active development by a team of developers.
17- Elasticsearch
ElasticSearch is a popular open-source enterprise-grade full-text search. It has REST-API and supports real-time indexing and scaling.
The ndx is a full-text search engine library written in Node.js. It supports multiple fields, real-time indexing, inverted text, text queries and serializable index.
This library has a small memory footprint which is optimized for mobile applications and web apps.
Srchx is a standalne full-text search engine built on Bleve, but it supports multiple storage Scorch, BoltDB, LevelDB and Badger.DB It larverages full CPU cores and comes with REST-API.
LIFTI is .NET based full-text search indexer for .NET-based applications.
21- Tantivy
A full-text search engine and indexing server built with Rust.
As our list comes to an end, we listed the best active full-text search projects with a good support. If you know of anyone that we didn't include on this list, please let us know in a comment or a message.
Related Articles in List
13 open-source free react ui builder for building rich interfaces.
A React UI Builder is a tool that allows developers to create user interfaces with React, a popular JavaScript library, in a more visual and intuitive way. These UI builders often provide a drag-and-drop interface, making it easy to design interfaces without writing a lot of code. React UI Builders
21 Flat File Database Open-source, JavaScript, Rust, Python, Java, PHP, and Go
Flat-file databases, well, they're a kind of database that keep data in a plain text file, right? Every line of that text file holds a record, with fields split by delimiters, like commas or tabs. Some of them don't have the fancy relational structure of other
16 Free React Map Libraries for Google Maps, Leaflet, and SVG Maps
Welcome to your comprehensive guide for the best free React.js Map Libraries. This guide is designed to delve into an impressive range of 16 top-tier libraries. Each one has been carefully selected for its ability to enhance your React.js applications with interactive and customizable map features. Our coverage
30+ React Data Visualization and Chart Libraries
As a React developer, there's a high probability that you've encountered scenarios where you needed to incorporate some form of visualization into your applications. This could be anything from simple graphs to complex interactive visuals. The question then arises - which library should you choose for
17 Free Open-source WebGL Libraries with WebGPU Support
WebGL is a JavaScript API that lets you create interactive 3D and 2D graphics in any web browser that supports it, without needing plug-ins. It's fully integrated with other web standards, so you can use GPU-accelerated physics and image processing and effects in the web page canvas. WebGPU,
17 Free Open-Source Flat-File CMS in PHP (Laravel, Symphony, and Pure PHP)
Flat-file content management systems (CMSs) expertly address the issue of eliminating the need for a database to store content and configuration. Relying exclusively on flat-files instead of a database, they robustly safeguard against SQL-injection. Moreover, they optimally utilize server resources, far more efficiently than their traditional database-dependent CMS counterparts. Indeed,
10 Free Portable DICOM Viewers To Display DICOM Images Directly from CD/ DVD and USB-Drive
A portable DICOM viewer, is an app that you can run it directly to view DICOM files without installation. It is a useful feature if you want to run, view and display DICOM images and media with portable media as USB-drive, DVD, or CD ROM. Benefits of using Portable DICOM

INCEpTION is an open-source Semantic Annotation
INCEpTION is a sophisticated semantic annotation platform, diligently developed by the UKP Lab at the esteemed Technical University of Darmstadt. Its primary objective is to centralize a diverse range of semantic annotation tasks into a single, user-friendly web-based platform. This innovative open-source free platform revolutionizes the annotation process by simplifying
- Dictionaries
- Enterprise Support
- Package Matrix
- Development
- Sphinx Tools
- Open Projects
- Documentation
- Case-Studies
- Powered by Sphinx
Full-Text Diary
Sphinx 3.7.1 released.
- vector indexes for ANN searches
- percolation indexes for "reverse" searches
- unified attr_xxx syntax for index schemas in configs
- indexer-side joins over SQL and CSV
- user authentication
- REPLACE ... KEEP clause
- searchd decode command to decode API crash dumps
Sphinx 3.5.1 released
Sphinx 3.3.1 released, sphinx meetup in moscow on feb 28, sphinx 3.1.1 released, sphinx 3.0.3 released, sphinx 3.0.2 released.
News » Mar 22, 2012. Spring News: 2.0.4-release, Webinar & Conference Schedule
We are proud to announce availability of the Sphinx 2.0.4-release another version of the 2.0.x branch which contains several major fixes and many other minor improvements. Upgrading to this latest release is highly recommended for those utilizing Real-Time Indexes.
Read more...
- Mailing list
- Development/Git
- Open Semantic Desktop Search
- Edit on GitHub
Open Semantic Desktop Search (VM)
Free software for your own desktop search engine for full text search, exploratory search and text analysis on windows or mac.
Open Semantic Desktop Search is free open source software for your own desktop search engine with integrated text analytics and research tools for full text search, exploratory search & text mining in large document sets, many PDF files, Word documents and many other file formats on Windows or Mac.
Desktop search engine package as virtual machine for single Linux, Windows or Mac users
The free software Open Semantic Desktop Search based on Open Semantic Search is the all in one package for desktop users (including Solr search server, user interfaces, open source search tools and connectors) as virtual machine image for full text search, exploratory search, analytics and text mining in many documents on your own desktop computer or notebook on Linux , Windows or iOS (Mac) .
Installation and configuration
Like described in the tutorial with screenshots how to install and configure the Open Semantic Desktop Search virtual machine just import the appliance file into Virtual Box and in the settings of the virtual machine add shared folders pointing to your documents directory or directories.
Starting the search engine
- Start Virtual Box
- Start the virtual machine (VM) " Open Semantic Desktop Search "
Search, explore and analyse
Use powerful research tools for full text search, exploration, discovery, analysis, text mining and document mining
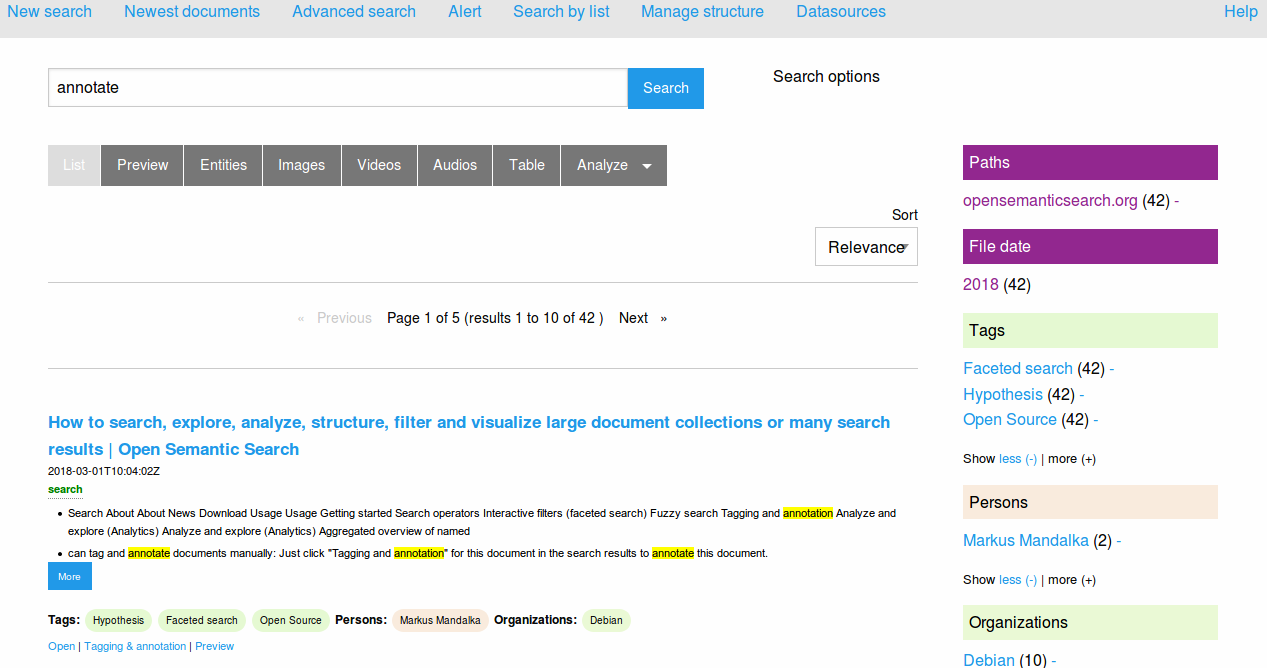
Index documents
Indexing documents from all configured shared folders will be started automatically after starting the Desktop Search virtual machine.
You can index new documents which were added after the start of the virtual machine without need to restart:
- Click or touch the menu Activities .

- Click or touch the launcher " Index all documents for search " for recrawling all documents and subfolders in your document folder

Launch the search user interface
The search interface will be started automatically after new documents were added to the document processing queue.
If you close the browser, you can open the search interface again: Launch the search user interface by clicking the launcher " Search for documents " or one of the other powerful research tools.
Lightning-fast Open Source Search
No phd required., the open source alternative to algolia + pinecone, the easier to use alternative to elasticsearch.
Typesense is a modern, privacy-friendly, open source search engine meticulously engineered for performance & ease-of-use .
It uses cutting-edge search algorithms that take advantage of the latest advances in Hardware Capabilities & Machine Learning.
- Search-as-you-type
- Autocomplete
- Faceted Navigation
- Fuzzy Search
- Vector Search
- Semantic Search
- Recommendations
- LLM Augmentation
- Geo-Distributed Cache
Trusted by Teams of all Sizes

Features you love, minus the complexity
Typo tolerance.
Spellng Mistakes? Not a problem. Typesense automatically tries to correct typos.
Tunable Ranking
Tailor your results to perfection via flexible and fast query-time ranking.
Merchandising
Pin specific records in a particular position to feature or merchandize them.
Show results for pants when users search for trousers, or vice-versa, when you define them as synonyms.
Multi-tenant API Keys
Store multiple users’ data in a single index, create API keys for each user that restrict access to just their data.
Dynamic Sorting
Sort records on the fly by any fields in your document. For eg: sort by price, sort by popularity, etc. No duplicate indices needed.
Grouping & Distinct
Provide more variety in your results by grouping results. Eg: combine all color variations of a shirt into a single result.
Filtering & Faceting
Only fetch records that match a given filter. Aggregate field values and get counts, min, max and avg of values across records.
Search & sort results within a certain distance from a latitude/longitude or within a polygon region.
Federated Search
Search one or more collections in a single query. Eg: search for both products and brands, given a single search query.
Vector & Semantic Search
Automatically generate embeddings using built-in ML models or OpenAI / PaLM API and do semantic search or nearest-neighbor search.
Easy High Availability
Build a resilient production-grade search service, with a few simple steps.
Batteries-Included Developer Experience
1. run typesense, 2. index data, and, that's it search away., api libraries & plugins in your favorite languages, compose powerful search & discovery user interfaces, quickly., ⚡ 🔍 🎵 instantly search 32 million songs, ⚡ 🔍 📚 instantly search 28 million books, ⚡ 🔍 🥘 instantly search 2 million recipes, ⚡ 🔍 ⌨️ instantly search 1 million linux commits, ⚡ ⌨️ spell checker with autocomplete & autocorrect, ⚡ 🔍️ ⚡ federated search experiences, ⚡ 🔍️ ⛓ semantic search experiences, build lightning-fast browsing experiences with typesense, besides just text-based search., ⚡ 🔍 📦️ e-commerce storefront browsing experience, ⚡ ⌨️ findxkcd browse & find xkcd comics by topic, ⚡ 🔍 📦️ e-commerce storefront with next.js + typesense, ⚡ 🔍 🌎️ airbnb browsing experience with 1m listings., backed by responsive support, we also offer concierge onboarding and prioritized support, for when you need it..
What is Full-Text Search and How Does it Work?
It's no secret that the amount of data generated globally is geometrically exploding. In fact, it's estimated that by the end of 2025, there will be 181 zettabytes of data in existence for the first time ever (for context, one zettabyte is equal to one sextillion bytes)! And, of those 181 zettabytes, 80% is anticipated to be unstructured data .

However, this also highlights a significant issue for data users of all kinds. Unstructured data, specifically unstructured text data, can neither be housed in nor queried by traditional relational databases. Further, traditional queries, which only search for exact text matches, aren't very helpful in that the user often only knows the topics or key ideas they are searching for in the text data.
The solution to this problem is full-text search. Full-text search enables users to access their unstructured text data in a way that is both intuitive and efficient while this data is stored optimally in nonrelational, NoSQL databases . Read on to learn what full-text search is, how it works, and examples of how it's used.
Table of contents
What is full-text search?
Types of full-text search.
- Full-text indexing
Full-text search example
Considerations when using full-text search.
Unlike traditional search methods that rely on exact word or phrase matches, a full-text search refers to a search of all of the documents' contents within the full-text queries’ range(s) that are relevant. This includes topic, phrasing, citation, or additional text attributes.
There are a variety of ways to conduct full-text searches. Each type has its own advantages and, much like the tools in a toolbox, is designed to address specific needs. Here are some of the most common types:
Simple full-text search : Simple full-text searches are very basic in that users enter keywords or phrases to find documents containing those specific terms.
- Best use : These searches are often used as quick searches seeking general information.
Boolean full-text search : This type of search uses Boolean operators (e.g., AND, OR, NOT) to either combine or exclude specific keywords in the search query. This not only provides more control of the search results but also helps users narrow down broad topics to the specific information they are seeking.
- Best use : Often used in complex queries using logical relationships between terms, Boolean full-text searches help users save time and enhance query relevance.
Fuzzy search : Fuzzy search allows the user to find text that is a “likely” match, meaning that misspelled words, typos, etc. in the desired term can be analyzed as matching user parameters.
- Best use : These searches are helpful when searching through documents that often have non-traditional spellings, typos, or other irregularities.
Wildcard search : Wildcard searches include non-alphanumeric characters (e.g., ?, *) representing unknown portions of words. This allows the user to search for variations of words (e.g., part, parted, parting) or partial matches (e.g., summertime, summer vacation, summer).
- Best use : These searches are helpful when users want to account for different forms or correct spelling variations of a word.
Phrase search : This search seeks an exact phrase where the words of the phrase queried appear within the document in the order specified.
- Best use : Phrase searches are often used in queries searching for contextually related terms in long documents (e.g., searching for "2024 income tax brackets" within an IRS website).
Proximity search : Proximity searches identify and retrieve documents containing specific terms within a set number of words, phrases, or paragraphs from each other.
- Best use : Proximity searches are useful in narrowing down results when searching long documents on a broad topic. For example, a treatise on marine conservation may include information on all types of marine environments (e.g., deep sea, estuaries, mangroves) but by using a proximity search index when looking for mangrove conservation information, most relevant mangrove information will be retrieved from the document.
Range search : Range searches look for terms within a numerical or alphabetical range specified by the user.
- Best use : Range searches are helpful when ranges such as dates, currency values, or alphanumeric medical coding are of interest to a user.
Faceted search : This type of search helps refine results using predefined categories and specific attributes (e.g., facets) of the topic.
- Best use : These searches are used every day in ecommerce (e.g., a medium, cotton, button-down, blue, dress shirt). The descriptors or attributes — such as medium, blue, and dress shirt — are all facets of the clothing desired by the user.
Full-text search queries
Full-text queries are used within full-text searches to define the specific terms, parameters, etc. required by the user. Further, full-text queries enable the discovery of additional content of which the user may be unaware via multiple methods, including the following:
Natural language processing (NLP) : Full-text searching often incorporates NLP techniques to understand the context, semantics, and relationships between words in full-text queries and the text in documents. This provides accurate and contextually relevant results, even though the user may not know specific terms or phrases they should include in their full-text search queries.
Synonym expansion : Full-text search engines often employ synonym expansion capabilities. This means that the full-text search engine is able to identify alternative words or phrases that have the same meaning (e.g., synonyms) as those included in the users' full-text search query. Given this expansion of relevant search terms, more relevant information is gathered for the user despite the user not including these particular words (e.g., synonyms) in their initial full-text query.
Ontologies and taxonomies : Using ontologies or taxonomies assists in the grouping of terms into hierarchies based on term relationships. Using these hierarchies, full-text searching is enhanced in that both broader and narrower terms relevant to the user's query can be returned. This provides an accurate and more comprehensive set of results.
Fuzzy matching : Fuzzy matching algorithms enable the database engine to find approximate search term matches for their query. This means that content containing misspelled words, overlooked typos, or other language variations that actually do match the query but would be overlooked by traditional searches are identified and collected for the user.
Relevance ranking : In relevance ranking, sophisticated algorithms are employed to consider such factors as frequency of term usage and term proximity within documents to help identify documents that may contain unexpected but highly relevant information relating to the user's query.
The combination of these techniques enhances the ability of full-text search systems to uncover relevant information, making them powerful tools for unstructured text data exploration and discovery — even when users may not have a full understanding of the breadth and depth of the topic they are investigating.
Full-text search indexing
Full-text search involves reviewing large numbers of documents and vast amounts of text. Web search services often use full-text search to retrieve relevant results from the internet — be it web page content, online .PDFs, and more. Given the volume of text data involved, a technique to handle the search volume is required — it's called full-text indexing. A full-text search index is a specialized data structure that enables the fast, efficient searching of large volumes of textual data.
To create a full-text search index, each text field of a dataset (e.g., document) is analyzed. First, diacritics (marks placed above or below letters, such as é, à, and ç in French) are removed. Then, based on the language the text is written in, the algorithms remove filler words and only keep the stem of the terms. This way, “to eat” and “eating” are classified as the same root word: “eat."

Next, all text is converted to either all uppercase or lowercase text. Additional steps may also be included depending upon the specific analyzer that is being used to develop the full-text index.

Finally, the index is created, storing references to where each term (e.g., word, phrase) can be found within the document where it resides.
Summary of full-text index characteristics
Mapping terms to documents : The main function of full-text indexes is to map terms (e.g., words, phrases, numbers) back to the documents where they reside. During the creation of the index, document content is reviewed and a link between terms and their respective documents is created.
Enhanced query speed : Once the full-text index is created, it allows for fast lookup and retrieval of documents relevant to a user's search query. Instead of scanning through all the content of every document or all web pages, the search engine can quickly identify the documents that contain the specified terms by consulting the index.
Optimization : In addition to enhanced query speed, additional optimizations to enhance index speed and storage efficiency are applied. Data caching, data compression, and other data structure optimizations are often employed to create leading-class full-text search systems.
Full-text index types
There are various types of full-text indexes to choose from. Search requirements, data type and volume, and query complexity are key points of consideration for the user when selecting the full-text index method. In addition, some users may choose to employ more than one indexing method to optimize performance and address data storage concerns. Two common full-text indexes include inverted indexes and B-tree indexes.
Inverted index : Inverted indexes are the most commonly used. These indexes store the mapping of terms to the documents in which they're contained. They enable rapid lookups during searches (i.e., search the index rather than all the documents) and optimize the search process.
Within inverted indexes, some of the additional functions occurring behind the scenes include:
Compression : Data compression techniques are applied to reduce index data storage requirements.
Positioning : Additional information related to where the selected term(s) appear in a document is included, enabling proximity and phrase queries.
Frequency : Rather than mapping terms, documents are mapped. This is useful when analyzing the number of times a term appears in a document.
N-grams : Text is broken down into N-grams (i.e., a contiguous sequence of characters or words). For example, the phrase "The slow tortoise beat the lazy hare" could be broken down into N-1, "Tortoise beat the lazy hare"; N-2, "The slow tortoise beats"; N-3, "Tortoise beats the lazy"; etc. N-gram indexing enables partial matching and wildcard queries.
B-trees and B+ trees : B-trees and B+ trees are often used when full-text search is integrated into a relational database. Specifically, they are often used for range queries (e.g., a date range, a range of currency values).
Full-text search can have many different uses. For example, an inverted index could be used to look for a dish on a restaurant menu or for a specific feature in the description of an item on an e-commerce website. In addition to searching for particular keywords, a full-text search can be augmented with search features such as fuzzy-text and synonyms. In our example, the results for a word such as “pasta” would return not only items such as “ Pasta with meatballs” but could also return items such as “ Linguine Carbonara” using a synonym, or “ Psta ” using a fuzzy search.
In the example of Apache Lucene , the open-sourced search library, it uses an inverted index to locate restaurant menu items and acts as an extensive glossary for any matching documents.
You can find a fully functional demo of a similar full-text search for menu items at https://www.atlassearchrestaurants.com/ .
Implement full-text search in SQL
To implement our restaurant menu full-text search example in a SQL database, a full-text index on each column to be indexed must be created. In MySQL, this would be done with the FULLTEXT keyword.
Then, you will be able to query the database using MATCH and AGAINST.
While this index will increase the search speed for your queries, it does not provide you with all the additional capabilities that you might expect. To use features such as fuzzy search, typo tolerance, or synonyms, you will need to add a core search engine such as Apache Lucene on top of your database.
Implement a full-text search example in MongoDB Atlas
Implementing a full-text search engine in MongoDB Atlas simply requires clicking a button . The user goes to any cluster and selects the “Search” tab. From there, click on “Create Search Index” to launch the process.

Once the index is created, you can use the $search operator to perform full-text searches.
This aggregation is the most simple query used with MongoDB Atlas Search. Rich queries — including typo-tolerance , search term highlighting , and synonym search — can also be built. Behind the scenes, Atlas Search uses Apache Lucene, so you don't have to add the engine yourself.
If you don't have a MongoDB Atlas account, you can sign up for one for free right now. Once you have your account set up, you'll be able to try out Atlas Search in the demo at the Atlas Search Restaurant Finder , or you can learn how to implement it using our tutorial on how to build a movie search application .
Before implementing a full-text search solution, it's important to consider the necessary features, architectural complexity, and costs related to your full-text searches. Here, we will use examples from MongoDB Atlas Search to illustrate each consideration.
- Necessary features
Adding a full-text index to your database will help optimize your text search and potentially minimize storage requirements. Still, you might need additional features, such as auto-complete suggestions, synonym search, or custom scoring for relevant results. Some examples from MongoDB Atlas Search include:
Rich querying capabilities : Using a wide range of operators , Atlas Search can do more than just search for text. It can also search for geo points and dates.
Fuzzy search : Users sometimes make mistakes as they type. With Atlas Search typo-tolerance , you can deliver accurate results, even with a typo or a spelling mistake.
Synonyms : Your data might use wording differently from what your users are searching for. You can use synonyms to define lists of equivalent words to deliver more relevant results to your users.
Custom scoring : If you have promoted content or content that is more relevant based on different variables (for example, at different times of the year), you can define that in a custom scoring function. This score will help push prioritized results to the top of the search results.
Autocomplete : Provide your users with suggestions to make their experience more seamless as they type.
Highlights : As the search results come back from your database, have them automatically highlight the searched words to help your users find more context on the results.
Interested in learning more? A complete list of MongoDB Atlas Search features is available.
- Architectural complexity
Adding additional components adds complexity to your application. To provide full-text search capabilities to your application, you will need an extra layer to take care of the indexing and provide you with the results.

With MongoDB Atlas Search, everything is integrated into your database. Software developers don’t need to worry about where to query — they can access data with a regular aggregation pipeline, just as they would with traditional data.

By removing that additional layer, software development is simplified and the associated overhead of implementing and maintaining different components in the architecture is avoided.
Whether a solution is built in-house or uses a third-party tool, additional costs are to be expected. On one hand, developing a solution in-house may incur high costs in terms of development time, mistakes, and overall hours. Conversely, even an open source solution comes at a price in terms of integration, maintenance, etc. This is why many software development teams start with an off-the-shelf solution that requires minimal effort to implement and maintain. The fixed cost of a third-party solution, in combination with a set deliverable timeframe, can make the most sense. Make sure to consider all these factors when evaluating the right full-text search solution for you.
Using a solution such as MongoDB Atlas Search reduces costs by removing underlying infrastructure maintenance and associated training. It also makes it easier to ramp up development teams as most are already familiar with using MongoDB to query their data.
Are you ready to discover how to ramp up your full-text searches? Here are some additional resources to help you learn more.
- What is MongoDB Atlas Search?
- What is MongoDB Compass?
- MongoDB Community
- Self-managed text queries
What is a full-text search?
What are the different types of full-text search.
- Simple full-text search
- Boolean full-text search
- Fuzzy search
- Wildcard search
- Phrase search
- Proximity search
- Range search
- Faceted search
What is a full-text search query?
Full-text queries are used within full-text searches to define the specific terms, parameters, etc. required by the user.
What are the different types of full-text search queries?
- Natural language processing (NLP)
- Synonym expansion
- Ontologies and taxonomies
- Fuzzy matching
- Relevance ranking
What is a full-text search index?
What are the characteristics of full-text indexes.
- Mapping terms to documents
- Enhanced query speed
- Resource and storage optimization
What are the most common types of full-text indexes?
- Inverted index
- B-trees and B+ trees
How does full-text searching work?
What are some key considerations when using full-text search.
Harvey Cushing/John Hay Whitney Medical Library
- Collections
- Research Help
Free Full Text Biomedical Literature: Finding free full text online
- Finding free full text online
- What to do when you can't find free full text
- Before you leave Yale
Find free full text with browser extensions
- Get the Open Access Button This open source project links you to free, legal, full text articles. You can search from their website or through their API, but their browser extension is the most convenient. When you're on the page of a paywalled article, click the extension and it will look for an open access version of the article. And if it can't find one, it makes it easy to request a copy from the author.
- Get Unpaywall The browser extension Unpaywall, for Firefox and Chrome, adds a green tab beside research articles that you can read for free.
Free full text in Google and Google Scholar
Google and Google Scholar both include lots of material and use algorithms that are constantly being adjusted to highlight the "most relevant" results. Expect good recall, low precision, and little quality control.
When you search in Google Scholar, you'll see links labeled [PDF] to the right of search results. This connects you to full text from many resources: PubMed Central, ResearchGate, Academica.edu, or institutional repositories.
Do the same search in Google Scholar and Google, and you'll get different results. You can limit your Google results to PDFs by adding filetype:pdf to your search string; this can help you track down full text of articles, reports, and white papers.
- Google advanced search
- Google Scholar
Free full text in PubMed and PubMed Central
PubMed and PubMed Central are both free databases that you can search with high precision. To check which database you're using, look in the top left corner. Even though they look similar, there's an important difference! PubMed is a database of citations ; PubMed Central is a database of articles .
It's almost always better to look for articles about your topic in PubMed, which is much bigger and updated more quickly. We recommend searching PubMed Central in one particular situation: if you need to search for keywords in the full text of articles.
PubMed has a free full text filter on the results page. Look on the left, under text availability , and click on free full text . The results set for your search will get smaller, but all the remaining articles are easily available in free full text. Just click on the article title to get to the article page, then look for the full text link on the right.That full text link will bring you to the article's full text, maybe in PubMed Central or maybe somewhere else.
- PubMed Central

Other resources for free full text
- HINARI Are you affiliated with an educational or health care institution in a low-income country? Talk to your organization about registering for HINARI to get free access to literature from many scholarly publishers.
- Open Access Dissertations and Theses Use OATD to search almost four million theses and dissertations -- all open access. If you've been using Proquest Dissertations and Theses as a Yale affiliate, try this out.
- Open Science Framework Preprints "Preprints" are typically complete and public versions of articles before they have gone through peer review. Biomedical funders including the NIH and the Wellcome Trust have encouraged researchers to cite preprints as interim research products.
- Sci-Hub: an ethical conundrum You've probably heard about Sci-Hub, an online collection of article PDFs. Before you decide to use Sci-Hub, you should read about the ethical conflicts of their approach; you can start with the coverage in Science, linked above. Librarians don't endorse copyright infringement -- that's why we have recommended all these other pathways to free full text.
You found it, but should you use it? Critical appraisal
- Evidence-Based Medicine Worksheets Use these handy worksheets from Dana Biomedical Library at Dartmouth to appraise randomized control trials, systematic reviews and meta-analyses, practice guidelines, studies of diagnostic tests, prognosis studies, etiology studies, and qualitative studies. Don't outsource your critical thinking to journal editors and peer reviewers!
- Next: What to do when you can't find free full text >>
- Last Updated: May 17, 2021 10:42 AM
- URL: https://guides.library.yale.edu/freefulltext
Finding full text
- Getting started
- Full text from the library
- Google Scholar
- LibKey Nomad
- Browser tools
Free full text sources
- Full text not available
- Library help
Open Access FAQs
- Possible alternatives to access full text
- You found it, but should you use it?

More information on open access resources can also be found on the Guide links below:
- Grey Literature For open access theses and dissertations and conference proceedings explore our Grey Literature guide.
- Open Access For directories of open access journal /books and educational resources explore our Open Access guide.
Evaluate the resource for accuracy and credibility
If your resources are not retrieved from the library's databases, then closer scrutiny of the resource is required. The suggestions below will help you decide about the credibility of resource you found online and if you would want to use it in your paper.
Check if the article is published in a peer reviewed journal by checking these resources

- The journal's website: verify if it is a peer reviewed journal from the About pages
Use the following modules and checklists to evaluate the resources you found:
- Evaluating Information This module from Credo Research Skills, covers the basics of evaluating resources for authority, accuracy, and other criteria.
- Health Research Readiness: Module D Evaluating information Covers how to evaluate resources, including spotting predatory publishers and evaluating self-styled "experts".
- Dependability checklist A checklist from Deakin University to help critically evaluate the credibility of a resource.
- JBI critical appraisal tools JBI checklists assist in assessing the trustworthiness, relevance and results of published studies and opinion.
Ask a librarian if you are still unsure!
- << Previous: Browser tools
- Next: Full text not available >>
- Last Updated: Feb 12, 2024 4:56 PM
- URL: https://library.nd.edu.au/instruction/findfull
- Send Us A Tip
- Calling all Tech Writers

Best Full-Text Search Engines to Maximize Search Experience for Your Users in 2021

You might also like
Amazon cloud job cuts: lays off hundreds in cloud unit, elon musk grants free premium memberships to influential x users, apple developing robots for your home: is this the future of home tech.
Most applications and websites that operate vast and ever-increasing volumes of data cannot serve their customers well without implementing modern full-text search engines. Compared to traditional relational databases, full-text search engines allow for a much more relevant search and can quickly process larger quantities of structured, semi-structured, or unstructured texts using specific words or word combinations.
Today, there is no shortage of capable full-text search engine solutions in the market. Some of them are proprietary technologies, while others are open-source products. This post explains the full-text search concept and reviews the five best publicly available and proprietary solutions. Read on to find the one that meets your business needs in full.
What Is Full-Text Search?
Full-text search is a method of searching a single text or a collection of texts stored on a computer or in a full-text database. When processing an advanced linguistic text query, the search engine examines and analyzes all the words in every applicable document, seeking to match the criteria provided by the user.
As static sites become more of a trend and replace dynamic database-driven online resources, full-text search systems are turning into a much-needed, customizable tool for performing complex search operations.
The Benefits of Using a Full-Text Search Engine
The reasons for implementing a full-text search system are many and varied. Here are just a few advantages users can derive from such solutions:
- High query-processing/result-retrieving speed . The use of full-text search ensures a high speed of processing the user’s text query and obtaining accurate results for a vast number of documents across an extensive text database.
- Great accuracy and precision . Thanks to their highly sensitive recommendation algorithms and advanced relevancy ranking for organizing results, full-text search solutions provide a more accurate, personalized search experience for the user.
- Room for customization . The search logic and criteria of such solutions are flexible and can easily be configured to match the user’s more specific needs. The best solutions provide extensive support for keyword search, Google-style syntax search, Boolean operator search, etc.
- Support of static websites . Employing a full-text search solution ensures an improved experience for the user of static websites where the lack of dynamic features can make searching for a piece of content difficult, lengthy, and rather sloppy.
- Support of mobile applications . Modern mobile apps require quick and sophisticated search capabilities. Full-text search products implemented in mobile applications will allow to quickly and efficiently index and search all the documents, providing the user with accurate and relevant results.
Full-text search is not always the best possible technology for a website or app to rely on, and in some situations, a relational database with its excellent storing and structured data-manipulating capabilities will offer more measurable and successful results.
Top-4 Most Interesting Full-Text Search Solutions in 2021
To make sure you have all the essential information handy, here are the top-4 full-text search technological solutions worth exploring in 2021:
- Elasticsearch
ClickHelp and Algolia are the two best-known and most trusted closed-source full-text search solutions, while Sphinx and Elasticsearch are all ready-to-use open-source alternatives. Here is more about each of them to help you make a more informed user decision.
#1 ClickHelp
Known for enabling incredibly fast indexing speed and yielding accurate search results, ClickHelp is the most trusted closed-source full-text search engine in the 2021 tech market. The browser-based solution offers impressive searching, filtering, and reporting capabilities, supports the context-sensitive help feature, and uses taxonomies for improved search results.
This C++ -based full-text search engine server offers seamless performance on macOS, Windows, and Linux. It has a high index and search speed, integrates smoothly with MySQL and PostgreSQL, and comes with a rich API for the most prevalent programming languages (PHP, Java, Ruby, Python, Perl, and C++).
#3 Elasticsearch
Built on the Lucene library, Elasticsearch is the most popular open-source full-text search engine. The solution boasts both HTTP RESTful and Native Java APIs. Users love Elasticsearch for its excellent real-time index sharding and scaling capabilities.
Algolia is a well-known full-text search engine built on the SaaS model of business. This closed source solution is fast, dependable, and requires very little infrastructure. It can be used straight from the client or different services and offers an effortless integration at all times. Algolia offers customizable UI libraries for Angular, Vue, iOS, and Android.
Nothing can beat modern full-text search technologies in their high-speed search powers and the ability to sift through large volumes of data, delivering quick and accurate results. Most user-intensive apps and websites will surely benefit from the flexibility and customization potential of such products.
What full-text search solution do you trust the most? How well does it work for you? Which features are the most essential for a good full-text search engine? Feel free to speak up in the comments, and share the post with friends!
Doctor Fresh – Get Customized Water Purifier At Home
How and why make a hollywoodbets login, rohan mathawan.
Content Editor at Techstory Media | Technology | Gadgets | Written more than 5000+ articles about different niches from Tech to online real money gaming for reputed brands and companies. Get in touch Email: [email protected] For Business Enquires related to TechStory [email protected]
Recommended For You

The tech giant Amazon is restructuring, with job layoffs most recently occurring in its cloud computing subsidiary, Amazon Web Services (AWS). AWS announced layoffs affecting several hundred employees...

Elon Musk, the mastermind behind X, formerly known as Twitter, is shaking things up yet again. This time, he's handing out freebies to some of the platform's most...

According to reports, Apple Inc., the multinational technology company known for its modern gadgets and inventive products, is exploring the field of personal robots. A new report from...
Copy Protect PDF, MP3, MP4 and more, with Nexcopy USB Duplicator Systems .
Related News

How to Boop on Tumblr

DoJ Claims Apple Prevented Rise of Super Apps

How to Get Bankai Type Soul

How to Send a Gift Message on Instagram

How to See Hidden Replies on Twitter

How To Use Bankai in Type Souls
Tech and Business News from around the world. Follow along for latest in the world of Tech, AI, Crypto, EVs, Business Personalities and more. reach us at [email protected]
Advertise With Us
Browse by tag.
© 2024 Techstory.in
Welcome to Open Library

Read Free Library Books Online
Millions of books available through Controlled Digital Lending
Set a Yearly Reading Goal
Learn how to set a yearly reading goal and track what you read

Keep Track of your Favorite Books
Organize your Books using Lists & the Reading Log

Try the virtual Library Explorer
Digital shelves organized like a physical library

Try Fulltext Search
Find matching results within the text of millions of books

Be an Open Librarian
Dozens of ways you can help improve the library

Volunteer at Open Library
Discover opportunities to improve the library

Send us feedback
Your feedback will help us improve these cards
Trending Books

Preview Book
![The Adventures of Sherlock Holmes [12 stories] by Arthur Conan Doyle](https://covers.openlibrary.org/b/id/6717853-M.jpg "The Adventures of Sherlock Holmes [12 stories] by Arthur Conan Doyle")
Classic Books

Books We Love

Recently Returned

Authors Alliance & MIT Press

Browse by Subject
106,413 Books
Science Fiction
19,708 Books
13,158 Books
Biographies
23,867 Books
9,254 Books
20,451 Books
31,574 Books
53,440 Books
2,062,229 Books
50,785 Books
135,056 Books
Mystery and Detective Stories
15,488 Books
2,855 Books
77,010 Books
91,239 Books
Around the Library
Here's what's happened over the last 28 days. More recent changes .
About the Project
Open library is an open, editable library catalog, building towards a web page for every book ever published. more.
Just like Wikipedia, you can contribute new information or corrections to the catalog. You can browse by subjects , authors or lists members have created. If you love books, why not help build a library?
Latest Blog Posts
- 🎉 2023 Open Library Community Celebration 🎃 - October 30, 2023
- How do patrons prefer to read? - September 14, 2023
- Google Summer of Code 2023: Supercharging Subject Pages - August 25, 2023
Search code, repositories, users, issues, pull requests...
Provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications
Pure-Python full-text search library
mchaput/whoosh
Folders and files, repository files navigation.
About Whoosh
Whoosh is a fast, featureful full-text indexing and searching library implemented in pure Python. Programmers can use it to easily add search functionality to their applications and websites. Every part of how Whoosh works can be extended or replaced to meet your needs exactly.
Some of Whoosh's features include:
- Pythonic API.
- Pure-Python. No compilation or binary packages needed, no mysterious crashes.
- Fielded indexing and search.
- Fast indexing and retrieval -- faster than any other pure-Python, scoring, full-text search solution I know of.
- Pluggable scoring algorithm (including BM25F), text analysis, storage, posting format, etc.
- Powerful query language.
- Pure Python spell-checker (as far as I know, the only one).
Whoosh might be useful in the following circumstances:
- Anywhere a pure-Python solution is desirable to avoid having to build/compile native libraries (or force users to build/compile them).
- As a research platform (at least for programmers that find Python easier to read and work with than Java ;)
- When an easy-to-use Pythonic interface is more important to you than raw speed.
Whoosh was created and is maintained by Matt Chaput. It was originally created for use in the online help system of Side Effects Software's 3D animation software Houdini. Side Effects Software Inc. graciously agreed to open-source the code.
This software is licensed under the terms of the simplified BSD (A.K.A. "two clause" or "FreeBSD") license. See LICENSE.txt for information.
Installing Whoosh
If you have setuptools or pip installed, you can use easy_install or pip to download and install Whoosh automatically::
Learning more
Read the online documentation at https://whoosh.readthedocs.org/en/latest/
Join the Whoosh mailing list at http://groups.google.com/group/whoosh
File bug reports and view the Whoosh wiki at http://bitbucket.org/mchaput/whoosh/
Getting the source
Download source releases from PyPI at http://pypi.python.org/pypi/Whoosh/
You can check out the latest version of the source code using Mercurial::
Contributors 31
- Python 100.0%

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Int J Trichology
- v.3(2); Jul-Dec 2011
“Free Full Text Articles”: Where to Search for Them?
Ashish singh.
Consultant Dermatologist, Parkinsganj, Sultanpur, Uttar Pradesh, India
Manish Singh
1 Department of Neurosurgery, JIPMER, Pondicherry, India
Ajai Kumar Singh
2 Department of Neurology, Dr. Ram Manohar Lohia Institute of Medical Sciences, Vibhooti Khand, Gomti Nagar, Lucknow, Uttar Pradesh, India
Deepti Singh
3 Consultant Psychiatrist, Parkinsganj, Sultanpur, Uttar Pradesh, India
Pratibha Singh
4 Department of Obstetrics and Gynaecology, JIPMER, Pondicherry, India
Abhishek Sharma
5 Department of Surgical Oncology, Rajiv Gandhi Cancer Institute and Research Centre, Delhi, India
References form the backbone of any medical literature. Presently, because of high inflation, it is very difficult for any library/organization/college to purchase all journals. The condition is even worse for an individual person, such as private practitioners. The solution lies in the free availability of full-text articles. Here, the authors share their experiences about the accessibility of free full-text articles.
INTRODUCTION
Presently, in India nearly 314 medical colleges are providing undergraduate medical education in the form of MBBS, 163 colleges are providing doctor of medicine in diploma in Dermatology,Venereology and Leprosy (DVL), and 84 colleges are providing diploma in DVL.[ 1 – 3 ] In addition to this, 27 hospitals are providing diplomate of national board in diploma in Venereology and Dermatology.[ 4 ] On comparing this data with number of research articles published, the latter stands in a mediocre situation. One of the important cause responsible for the relatively less number of research publication is unavailability of free full-text articles. Research works, published by most of the journals, are paid. Many of the undergraduates or postgraduate students may not be able to purchase these high-cost journals or articles. In addition to this, many researchers may not be willing to spend money on journals. These are some of the situations where free full-text articles come for rescue, but many of the beginners may not be familiar about how to search these articles. In addition, free full-text articles are the first choice for many of the postgraduate students for their dissertation.
HOW TO APPROACH
In addition to journals which are fully Open Access, there are few other journals which operate through subscriptions as mainstream journals do, but which offer open access to the electronic versions of their articles after a delay of usually a year, or selectively for individual articles, provided the authors have paid an additional charge to “open up” the articles.[ 5 ]
Free full-text articles can be approached in the following ways.
Medknow Publications
Medknow Publications publish nearly 150 journals. They provide free access to the electronic editions of their journals.[ 6 ] Researchers just have to open the site www.medknow.com , fill the key word they require, and search. Alternatively, they can visit the search option, available in most of their journals site through www.journalonweb.com , fill the key word, and search across multiple journals. At times, this site alone provides sufficient number of references required for the purpose. The important dermatological journals published by Medknow Publications are Indian Dermatology Online Journal, Indian Journal of Dermatology, Indian Journal of Dermatology, Venereology, and Leprology, Indian Journal of Sexually Transmitted Diseases and AIDS, International Journal of Trichology, and Journal of Cutaneous and Aesthetic Surgery.[ 7 ]
PubMed Central and PubMed
PubMed Central is the United States National Library of Medicine's digital archive of biomedical and life sciences journal literature which provides free access to the full text of articles.[ 8 ] To search for free full-text articles on PubMed Central, one has to visit the site http://www.ncbi.nlm.nih.gov/pmc/ , write the topic/author/journal title, and search across all articles.
PubMed is a database of citations and abstracts for articles from thousands of journals. PubMed does not include full-text journal articles.[ 9 ] It includes links to full-text articles at many journal web sites as well as to most of the articles in PubMed Central.[ 10 ] Here, articles can be searched on the site http://www.ncbi.nlm.nih.gov/pubmed . Search can be restricted to contents free on web by using filter your results and clicking free full text.[ 11 ]
Directory of Open Access Journals
The directory aims to cover all open access scientific and scholarly journals that use a quality control system to guarantee the content.[ 12 ] It provides articles from 439 medicinal journals. Among them, 21 are from dermatology.[ 13 ] It includes Anais Brasileiros de Dermatologia, BMC Dermatology, Case Reports in Dermatology, Clinical Dermatology, Clinical Medicine Insights: Dermatology, Clinical, Cosmetic and Investigational Dermatology, Dermatología Peruana, Dermatology Online Journal,th Dermatology Reports, Dermatology Research and Practice, Egyptian Dermatology Online Journal, Indian Journal of Dermatology, Indian Journal of Dermatology, Venereology and Leprology, The Internet Journal of Dermatology, Journal of Clinical and Experimental Dermatology Research, Journal of the Egyptian Women's Dermatologic Society, Open Dermatology Journal, Revista Argentina de Dermatología, Surgical and Cosmetic Dermatology, Turk Dermatoloji Dergisi, Turkderm.[ 14 ] The disadvantage of directory of open access journals is that few of these journals are in languages other than English. Here, articles can be searched on the site http://www.doaj.org .
Electronic Resources in Medicine Consortium and National Medical Library
Electronic Resources in Medicine Consortium (ERMED) and National Medical Library (NML) are an excellent platform for obtaining free of cost recent journal articles for its member colleges. There is no membership fees charged from the Government Medical Colleges and institutions. The private colleges and institutions have to make payment per site price for e-sources purchased by the consortium in every calendar year.[ 15 ] Membership of the college can be checked from the site http://www.nmlermed.in/members.htm or volunteers can contact their library to check the membership and to get the user name and password of the site www.ermed.jccc.in allotted to their college.[ 16 ] In 2009, the number of ERMED members increased from 40 to 72 Government Medical Colleges/Institutes across the country.[ 17 ] At present, it covers nearly 32 journals of dermatology. It includes Acta Dermatoveneorologica Alpina, Pannonica et Adriatica, Acta Dermatovenerologica Croatica, Advances in Skin and Wound Care, American Journal of Clinical Dermatology, American Journal of Dermatopathology, Archives of Dermatological Research, Archives of Dermatology,, Asian Journal of Dermatology, BMC Dermatology, Clinical, Cosmetic and Investigational Dermatology, Clinical Dermatology, Contact Dermatitis, Dermatologic Surgery, Dermatology, Dermatology Nursing, Dermatology Online Journal, Dermatology Times, Indian Journal of Dermatology, Indian Journal of Dermatology, Venereology and Leprology, International Journal of Dermatology, Internet Journal of Dermatology, Journal of Drugs in Dermatology, Journal of Investigative Dermatology, Journal of the European Academy of Dermatology and Venereology, Medicine, Open Dermatology Journal, Pediatric Dermatology, Rosacea Review, Skin and Allergy News, Skin Pharmacology and Physiology, Turkdem-Archives of the Turkish Dermatology and Venerology and Turkish Journal of Dermatology.[ 18 ]
Journal articles related to the topic can be searched easily after signing in at the site www.ermed.jccc.in , followed by clicking search database.
Google, Google Scholar, and Yahoo
Google ( http://www.google.com ) and Yahoo search ( http://www.search.yahoo.com ) are two of the world's most hit web pages and two largest web-based search engines.[ 19 ] Usually these are the first search site for any scholar. They provide links for both paid and free articles. The disadvantage associated with these sites is that additionally they provide materials that may not give scholarly information. Many articles are repeated also. But the catch is that one article which is paid at one web link may be free at another web link. Google Scholar ( http://www.scholar.google.com ) provides a simple way to broadly search for the relevant scholarly literature and research.[ 19 ]
The Cochrane Library
The Cochrane Library provides high-quality review articles. The Cochrane Database of Systematic Reviews has an impact factor of 5.653 of 2009.[ 20 ] Articles can be searched on the site http://www.thecochranelibrary.com/view/0/index.html .
Public Library of Science
Public library of science is a nonprofit organization of scientists and physicians committed to making the world's scientific and medical literature a freely available public resource.[ 21 ] Everything published on this site is freely available throughout the world, for researchers to read, download, copy, distribute, and use.[ 22 ] Articles can be searched here on the site http://www.plos.org/search.php .
Free Medical Journals
Currently, total 2226 journals are available on this site.[ 23 ] Among them, nearly 30 are journals are related to dermatology and venereology and most of them are in English.[ 24 ] Some journals are available only a few months after the release. Journals can be searched on the site http://www.freemedicaljournals.com/fmj/DERMA.HTM .
It covers more than 125 medical journals and textbooks. After a simple, free registration, Medscape automatically delivers you the specialty site that best fits your profile.[ 25 ] After signing in at www.medscape.com , articles can be searched.
HighWire Press Stanford University
HighWire Press partners with independent scholarly publishers, societies, associations, and university presses to facilitate the digital dissemination of 1465 journals, reference works, books, and proceedings.[ 26 ] Articles can be searched on the site http://highwire.stanford.edu/ . It provides both free and paid articles.
Bioline International
Bioline International provides open access to peer reviewed bioscience journals published in developing countries.[ 27 ] Articles can be searched on the site http://www.bioline.org.br .
Indmed covers about 77 journals indexed from 1985 onwards. A portal medIND provides free full text access to 40 Indian medical journals.[ 28 ] Articles can be searched on the site http://medind.nic.in .
BioMed Central
BioMed Central is a Science, Technology, and Medicine publisher. All original research articles published by BioMed Central are made free and permanently accessible online immediately upon publication.[ 29 ] After free registration, journals can be searched over http://www.biomedcentral.com/browse/journals/ .
Geneva Foundation for Medical Education and Research
Important dermatology journals in English included in this site are Acta Dermato-Venereologica, Acta Dermatovenerologica Alpina, Pannonica et Adriatica, Annals of Dermatology, Archives of Dermatology, Asian Journal of Dermatology, BMC Dermatology, Case Reports in Dermatology, Clinical Medicine Insights: Dermatology, Clinical, Cosmetic and Investigational Dermatology, Dermato-Endocrinology, Dermatology Online Journal, Dermatology Reports, Dermatology Research and Practice, Dermatology Times, European Journal of Dermatology, Indian Journal of Dermatology, Indian Journal of Dermatology, Venereology and Leprology, International Journal of Trichology, Internet Journal of Dermatology, Journal of Clinical and Experimental Dermatology Research, Journal of Clinical and Aesthetic Dermatology, Journal of Clinical, Cosmetic and Investigational Dermatology, Journal of Investigative Dermatology, Journal of Skin Cancer, Journal of the Egyptian Women's Dermatologic Society, Leprosy Review, Open Dermatology Journal, Rosacea Review, Skin Therapy Letter, World Wide Wounds.[ 30 ] Journals can be seen on the site http://www.gfmer.ch/Medical_journals/Dermatology.htm .
The website of Italian Library Association
Here journals can be traced on the site http://www.aib.it/aib/commiss/cnur/peb/pebs.htm3 . This site provides both free and paid journal articles.
UK PubMed Central
UK PubMed Central (UKPMC) is a full-text article database that extends the functionality of the original PubMed Central (PMC) repository. UKPMC ( http://ukpmc.ac.uk ) has undergone considerable development since its inception in 2007 and now includes both a UKPMC and PubMed search, as well as access to other records such as Agricola, Patents, and recent biomedical theses. UKPMC also differs from PubMed/PMC in that the full text and abstract information can be searched in an integrated manner from one input box. All of the articles in UKPMC are “Free Access,” Not all content available in PMC is made available to UKPMC.[ 31 ]
The University of lowa libraries
Links to few free full-text articles are available at the site http://www.lib.uiowa.edu/eresources/genindexes.asp .
National library of medicine gateway
National library of medicine (NLM) is a user-friendly web-based system that searches not only MEDLINE but also several other NLM databases at the same time.[ 19 ] Articles can be searched here on http://gateway.nlm.nih.gov/gw/Cmd .
Medical Matrix
Medical Matrix ( http://www.medmatrix.org ) is a comprehensive guide to clinical medicine resources on the Internet.[ 19 ] Medical Matrix links to more than ten MEDLINE sites, including Gateway and PubMed and fee and open access sites.[ 19 ]
World Health Organization
Publications from World Health Organizations can be searched at the site http://www.who.int/publications/en/ .
British Medical Journal Group
Some low income and low middle income countries are entitled to free access of this site.[ 32 ] For other countries, all the articles are not free. Journals can be searched here at site http://group.bmj.com/products/journals/ . This site includes Journal of Sexually Transmitted Infections.
British medical journal (BMJ) Open is an online-only, open access general medical journal, publishing medical research from all disciplines and therapeutic areas.[ 33 ] The journal publishes all research study types, from study protocols to phase I trials to meta-analyses.[ 33 ] Articles can be searched at http://bmjopen.bmj.com/ .
Elsevier Journals
Few journals published by Elsevier, provide free access to non subscribers, after a predefined period of time has elapsed following the final publication.[ 34 ] The list of journals can be seen on website http://www.elsevier.com/wps/find/authorsview.authors/delayedaccess .
Free full-text articles play a pivotal role in updating the knowledge of physicians and researchers. They play important role in preparation of any manuscript or thesis, for the persons who cannot subscribe to these articles due to any reason. Authors believe that these articles will be useful for such persons. Authors request the readers to contribute any other link for free full-text articles they know.
Source of Support: Nil
Conflict of Interest: None declared.
- University of Utah
- ULibraries Research Guides
- * Marriott Library Research Guides
Comprehensive Searching in the Social Sciences
- Free Text or Keyword Searching
What is Free Text or Keyword Searching?
Why free text or keyword searching, how to search by keyword.
- Subject Searching
- Combining Keyword and Subject Searching
- Faceting for Inclusion and Exclusion
- Documenting the Process
- Further Resources
Subject Guide

When you search a database, or even a search engine like Google, most often you will pick out words and phrases directly from your research question or topic without basing them off any index. When we use natural language without consulting a subject index, this is keyword searching. Keyword searching relies on us to supply our search terms and in turn searches every part of an indexed article record unless otherwise specified.
For example, say your research topic is the effect of bullying on minority high school students. Your keywords could be "bullying" and "high school students," and the database would search every indexed field for those words and phrases.
Subject searching, discussed on the next page, allows us incredible specificity when searching. Keyword searching, however, allows us to broaden our search by including language not used in subject terms. In our example search, the subject in the database might be "Minority high school students," but we could broaden our search with the phrase "diverse high school students." The strength in keyword searching lies in its ability to include synonyms as a way to thoroughly search a topic; different writers, disciplines, and databases can speak of a single concept in vastly different ways, and keyword searches allow us to cover each of those different ways.
Keyword searches allow us to search more than the subject field and broaden our search to the title and abstract fields, for instance, or even the full text if available. This way, if the way we phrase a concept isn't in the subject terms, we still have a good chance of finding what we are looking for.
- Web of Science
Scopus is a research database whose purpose is to index articles from a broad array of disciplines. Therefore, it is a great place for systematic searching.
To do a keyword search in Scopus, type your first keyword or phrase into the Document Search bar, seen above. You can add other keywords or phrases with the AND operator or by clicking the + button to add more rows, allowing you to do more complicated searches. In the above example, we are searching for articles with "bullying" in the title, abstract, or keyword fields AND "minority high school students" OR "diverse high school students" in the same fields.

Most databases use multiple search boxes to build a search for you. However, if desired, you can build your own searches if you know the codes for the search fields. When we use the builder in the first example, the results page will show us what our search string looks like typed out. When you learn the field codes, you can type out these search strings. In the Advanced Search area of Scopus, it gives a list of the field codes, as well.
Hint: Use Boolean operators and nesting in your search strings, as demonstrated in the Search Strategies box on this page.

You can get a sense as to how scholars are describing a topic by looking at the author-supplied keywords in any article:

Web of Science is a research database whose purpose is to index articles from a broad array of disciplines. Therefore, it is a great place for systematic searching.
To do a keyword search in Web of Science, type your first keyword or phrase into the Basic Search bar, seen above. You can add other keywords or phrases with the AND operator or by clicking the + Add Row button to add more rows, allowing you to do more complicated searches. In the above example, we are searching for articles with "bullying" in all fields AND "minority high school students" OR "diverse high school students" in the same fields. You can get more specific by selecting specific fields, such as just title. However, All Fields means just that: it searches the entirety of a record.

Most databases use multiple search boxes to build a search for you. However, if desired, you can build your own searches if you know the codes for the search fields. When we use the builder in the first example, the results page will show us what our search string looks like typed out. When you learn the field codes, you can type out these search strings. In the Advanced Search area of Web of Science, it gives a list of the field codes, as well.

You can get a sense as to how scholars are describing a topic by looking at the author-supplied keywords on any article:

Search Strategies
Boolean Operators are used to connect and define the relationship between your search terms. When searching electronic databases, you can use Boolean Operators to either broaden or narrow your search results. The three Boolean Operators are AND , OR and NOT .
Boolean Operators
Boolean operators are simple words (AND, OR and NOT) used as conjunctions to combine or exclude keywords in a search, resulting in more focused search results.

- Broadens or expands your search
- Is used to retrieve like terms or synonyms
- Finds all items with either teenager OR adolescent
- In set theory and math, " union " is inclusive "OR". "OR" = teenager U adolescent
- Narrows or limits your search
- Used to retrieve unrelated terms
- Finds items with both diet and children
- In set theory and math, " intersection " is "AND". "AND" = diet ∩ children
- Finds the term "spider" not "monkey"
- Use the NOT operator with caution
- May eliminate relevant records
Note: AND is the default or implied operator in Usearch, Google, Scopus, PubMed, EBSCOhost, and most search interfaces. "ecotourism sustainable" is the same as "ecotourism AND sustainable"
In Usearch, EBSCOhost, SCOPUS, and PubMed, Boolean operators (AND, OR, NOT) must be entered in upper case .
Phrase Searching
Phrase searching is using quotations.
For instance:
"international olympic committee" "Utah tennis"
It finds the exact phrase, and items with words in the order typed. One exception is Scopus. Scopus uses curly brackets or braces for {exact phrase} searching. In Scopus, quotes are used for "loose/approximate phrase" searching.
Truncation Stemming
Truncation or stemming is using an asterisk *. It is also known as a wildcard. Truncation is a symbol that retrieves all the suffixes or endings of a word.
school* retrieves school, schools, schooling, schooled, etc. latin* retrieves latina, latino, latinx, latinos, latinas, latin, latinization, etc.
Note: In the Library of Congress, % (percent sign) is a single character wildcard and ? (question mark) is truncation for multiple characters.
Nesting is commonly used when combining more than one Boolean operator (OR, AND). Most search interfaces search left to right. Using parentheses in a search changes the order of operation.
(moral* OR ethic*) AND (assisted suicide OR euthanasia)
(ski or skis or skiing or snowboard*) and video*, proximity or adjacency operators.
Proximity operators allow you to find one word within a certain distance of another.
With (w), Near (n), Next (n), or Pre (p) are common proximity operators.
Note: Read the database help to see if proximity operators can be used in your searches.
Thanks to Alfred Mowdood for authoring these instructions.
- << Previous: Start Here
- Next: Subject Searching >>
- Last Updated: Jan 21, 2024 3:12 PM
- URL: https://campusguides.lib.utah.edu/systematicsearching
Search results for
Affiliate links on Android Authority may earn us a commission. Learn more.
Google Search may no longer be entirely free
Published on April 3, 2024
")
- Google is reportedly exploring ways to offer AI-powered Search features for a fee, potentially within existing subscriptions.
- The traditional ad-supported Google Search would remain available for free.
Google , the tech giant synonymous with online search, could be considering a radical change to its business model. According to a Financial Times report, the company is exploring ways to offer premium, AI-powered features within its core search product for a fee.
According to the report, sources familiar with Google’s plans suggest these advanced AI-powered search features could become part of Google’s existing subscription services like Gemini Advanced or Google One. Notably, the report indicates that even the premium tier of Google Search will continue to include ads, while the traditional version will remain free to use.
This potential shake-up seemingly stems from Google’s need to balance two priorities: integrating cutting-edge AI into its search experience while safeguarding the lucrative search advertising that forms its financial backbone. The company’s staggering $175 billion in search-related ad revenue last year underscores the stakes involved. Meanwhile, the meteoric rise of OpenAI’s ChatGPT has pushed Google into a race for AI dominance.
Would you pay for AI-powered Google searches?
Google began testing its AI-powered search service, known as the Search Generative Experience (SGE) , in May of last year. SGE offers AI-powered summaries and responses to queries, along with the traditional presentation of links and advertising. The SGE experience has been purely opt-in until recently, when Google started testing it as a default experience for a limited set of users. However, the company has been slow to incorporate these SGE features into its main search engine, likely due to the high computational costs associated with generative AI models.
While SGE offers potential user benefits, it simultaneously challenges the foundation of Google’s current business model. The ability of AI to provide comprehensive answers could lead to a decline in user clicks on website links, resulting in fewer ad impressions and potentially jeopardizing Google’s primary revenue stream.
The report further claims that Google’s engineers are already developing this technology, but a conclusive decision and a launch timeline remain uncertain. Will you pay for a better Google Search experience? Let us know in the comments below.
To revisit this article, visit My Profile, then View saved stories .
- Backchannel
- Newsletters
- WIRED Insider
- WIRED Consulting
By Benj Edwards, Ars Technica
OpenAI Can Re-Create Human Voices—but Won’t Release the Tech Yet
Voice synthesis has come a long way since 1978’s Speak & Spell toy, which once wowed people with its state-of-the-art ability to read words aloud using an electronic voice. Now, using deep-learning AI models , software can create not only realistic-sounding voices but can also convincingly imitate existing voices using small samples of audio.
Along those lines, OpenAI this week announced Voice Engine, a text-to-speech AI model for creating synthetic voices based on a 15-second segment of recorded audio. It has provided audio samples of the Voice Engine in action on its website .
Once a voice is cloned, a user can input text into the Voice Engine and get an AI-generated voice result. But OpenAI is not ready to widely release its technology. The company initially planned to launch a pilot program for developers to sign up for the Voice Engine API earlier this month. But after more consideration about ethical implications, the company decided to scale back its ambitions for now.
“In line with our approach to AI safety and our voluntary commitments, we are choosing to preview but not widely release this technology at this time,” the company writes. “We hope this preview of Voice Engine both underscores its potential and also motivates the need to bolster societal resilience against the challenges brought by ever more convincing generative models.”
Voice cloning tech in general is not particularly new—there have been several AI voice synthesis models since 2022, and the tech is active in the open source community with packages like OpenVoice and XTTSv2 . But the idea that OpenAI is inching toward letting anyone use its particular brand of voice tech is notable. And in some ways, the company's reticence to release it fully might be the bigger story.
OpenAI says that benefits of its voice technology include providing reading assistance through natural-sounding voices, enabling global reach for creators by translating content while preserving native accents, supporting non-verbal individuals with personalized speech options, and assisting patients in recovering their own voice after speech-impairing conditions.
But it also means that anyone with 15 seconds of someone's recorded voice could effectively clone it, and that has obvious implications for potential misuse. Even if OpenAI never widely releases its Voice Engine, the ability to clone voices has already caused trouble in society through phone scams where someone imitates a loved one's voice and election campaign robocalls featuring cloned voices from politicians like Joe Biden.
Also, researchers and reporters have shown that voice-cloning technology can be used to break into bank accounts that use voice authentication (such as Chase's Voice ID ), which prompted US senator Sherrod Brown of Ohio, the chair of the US Senate Committee on Banking, Housing, and Urban Affairs, to send a letter to the CEOs of several major banks in May 2023 to inquire about the security measures banks are taking to counteract AI-powered risks.
OpenAI recognizes that the tech might cause trouble if broadly released, so it's initially trying to work around those issues with a set of rules. It has been testing the technology with a set of select partner companies since last year. For example, video synthesis company HeyGen has been using the model to translate a speaker's voice into other languages while keeping the same vocal sound.

David Kushner

Andy Greenberg

Jenna Scatena
To use Voice Engine, each partner must agree to terms of use that prohibit "the impersonation of another individual or organization without consent or legal right." The terms also require that partners acquire informed consent from the people whose voices are being cloned, and they must also clearly disclose that the voices they produce are AI-generated. OpenAI is also baking a watermark into every voice sample that will assist in tracing the origin of any voice generated by its Voice Engine model.
So, as it stands now, OpenAI is showing off its technology, but the company is not yet ready to put itself on the line (yet) for the potential social chaos a broad release might cause. Instead, the company has re-calibrated its marketing approach to appear as if it is warning all of us about this already-existing technology in a responsible way.
"We are taking a cautious and informed approach to a broader release due to the potential for synthetic voice misuse," the company said in a statement. "We hope to start a dialogue on the responsible deployment of synthetic voices and how society can adapt to these new capabilities. Based on these conversations and the results of these small scale tests, we will make a more informed decision about whether and how to deploy this technology at scale."
In line with its mission to cautiously roll out the tech, OpenAI has provided three recommendations for how society should change to accommodate its technology in its blog post . These steps include phasing out voice-based authentication for bank accounts, educating the public in understanding "the possibility of deceptive AI content," and accelerating the development of techniques that can track the origin of audio content, "so it's always clear when you're interacting with a real person or with an AI."
OpenAI also says that future voice-cloning tech should require verifying that the original speaker is "knowingly adding their voice to the service" and creating a list of voices that are forbidden to clone, such as those that are "too similar to prominent figures." That kind of screening tech may end up excluding anyone whose voice might naturally and accidentally sound too close to a celebrity or US president.
Tech Developed in 2022
According to the company, OpenAI developed its Voice Engine technology in late 2022, and many people have already been using a version of the technology with pre-defined (and not cloned) voices in two ways: The spoken conversation mode in the ChatGPT app released in September and OpenAI's text-to-speech API that debuted in November of last year.
With all the voice-cloning competition out there, OpenAI says that Voice Engine is notable for being a “small” AI model (how small, exactly, we do not know). But having been developed in 2022, it almost feels late to the party. And it may not be perfect in its cloning ability. Previous user-trained text-to-voice models like those from ElevenLabs and Microsoft have struggled with accents that fall outside their training dataset.
For now, Voice Engine remains a limited release to select partners.
This story originally appeared on Ars Technica .
You Might Also Like …
In your inbox: Introducing Politics Lab , your guide to election season
Think Google’s “Incognito mode” protects your privacy? Think again
Blowing the whistle on sexual harassment and assault in Antarctica
The earth will feast on dead cicadas
Upgrading your Mac? Here’s what you should spend your money on

Reece Rogers

Kate Knibbs

Steven Levy

Louise Matsakis

Will Knight

Caroline Haskins
COMMENTS
9- Typesense. Typesense is a free open-source search engine with user and developer-friendly functionalities. It supports full-text search, automatic suggest, ranking results, allows a wide range of filters and facets, and it's also a typo tolerant. Typesense. Lightning-fast, open source search engine for everyone.
Sphinx is an open source full text search server, designed with performance, relevance (search quality), and integration simplicity in mind. Sphinx lets you either batch index and search data stored in files, an SQL database, NoSQL storage -- or index and search data on the fly, working with Sphinx pretty much as with a database server.
Easy full text search in multiple data sources and many different file formats: Just enter a search query (which can include powerful search operators) and navigate through the results. Thesaurus & Grammar(Semantic search) Based on a thesaurus the multilingual semantic search engine will find synonyms, hyponyms and aliases, too.
Open Semantic Desktop Search is free open source software for your own desktop search engine with integrated text analytics and research tools for full text search, exploratory search & text mining in large document sets, many PDF files, Word documents and many other file formats on Windows or Mac.
Universal personal search engine, powered by a full text search algorithm written in pure Ink, indexing Linus's blogs and private note archives, contacts, tweets, and over a decade of journals. search-engine full-text-search torus-dom ink-programming-language Updated Nov 6, 2022; ...
MiniSearch addresses use cases where full-text search features are needed (e.g. prefix search, fuzzy search, ranking, boosting of fields…), but the data to be indexed can fit locally in the process memory. While you won't index the whole Internet with it, there are surprisingly many use cases that are served well by MiniSearch.By storing the index in local memory, MiniSearch can work offline ...
Search meets 2024. Typesense is a modern, privacy-friendly, open source search engine meticulously engineered for performance & ease-of-use . It uses cutting-edge search algorithms that take advantage of the latest advances in Hardware Capabilities & Machine Learning. Search-as-you-type. Autocomplete.
Full-text search. Full-text search is meant to search large amounts of text. For example, a search engine will use a full-text search to look for keywords in all the web pages that it indexed. The key to this technique is indexing. Indexing can be done in different ways, such as batch indexing or incremental indexing.
Orama is a full-text and vector search engine. This allows you to adopt different kinds of search paradigms depending on your specific use case. To perform vector or hybrid search, you can use the same search method used for full-text search.
Elasticsearch is a search server based on Lucene. It provides a distributed, multitenant-capable full-text search engine with a RESTful web interface and schema-free JSON documents. Elasticsearch is developed in Java and is released as open source under the terms of the Apache License. The advantages over other FTS (full text search) Engines are:
In text retrieval, full-text search refers to techniques for searching a single computer-stored document or a collection in a full-text database.Full-text search is distinguished from searches based on metadata or on parts of the original texts represented in databases (such as titles, abstracts, selected sections, or bibliographical references).. In a full-text search, a search engine ...
Search PMC Full-Text Archive Search in PMC. Advanced; Journal List; PubMed Central ® (PMC) is a free full-text archive of biomedical and life sciences journal literature at the U.S. National Institutes of Health's National Library of Medicine (NIH/NLM) About PMC Discover a digital archive of scholarly articles, spanning centuries of scientific ...
PubMed has a free full text filter on the results page. Look on the left, under text availability, and click on free full text. The results set for your search will get smaller, but all the remaining articles are easily available in free full text. Just click on the article title to get to the article page, then look for the full text link on ...
Here are some alternatives to access full text research articles, including general platforms and specific open access search engines. arXiv. arXiv is a preprint archive mainly for physics, mathematics, computer sciences, and related sciences. ... Free full text of biomedical and life sciences journal literature at the U.S. National Library of ...
The dtSearch Engine also works on cloud platforms like Azure and AWS. dtSearch Instantly Search Terabytes, dtSearch document filters, search all data types, Over 25 full-text and metadata search features, Developers: add instant search and data support, The Smart Choice for Text Retrieval® since 1991.
Full-text search is a method of searching a single text or a collection of texts stored on a computer or in a full-text database. When processing an advanced linguistic text query, the search engine examines and analyzes all the words in every applicable document, seeking to match the criteria provided by the user.
The author selected the Open Internet/Free Speech Fund to receive a donation as part of the Write for DOnations program. Introduction. ... Full-text search engines typically assign a relevance score to the search results, indicating how well they match the search query. MongoDB also does this, but the search relevance is not visible by default.
2. You can use the library Bsa.Search.Core to search in .Net. The library contains 4 index types: MemoryDocumentIndex - fast memory index. DiskDocumentIndex stores the index on disk. FileDocumentIndex - indexing files. ShardDocumentIndex - stores large indexes on disk of more than 3 million documents.
October 30, 2023. September 14, 2023. August 25, 2023. Open Library is an open, editable library catalog, building towards a web page for every book ever published. Read, borrow, and discover more than 3M books for free.
Whoosh is a fast, featureful full-text indexing and searching library implemented in pure Python. Programmers can use it to easily add search functionality to their applications and websites. Every part of how Whoosh works can be extended or replaced to meet your needs exactly. Some of Whoosh's features include:
Free full-text articles can be approached in the following ways. Medknow Publications. Medknow Publications publish nearly 150 journals. ... are two of the world's most hit web pages and two largest web-based search engines. Usually these are the first search site for any scholar. They provide links for both paid and free articles.
Most reliable full text indexer for Windows. Indexes more deeply than MS Search, more reliably than Copernic or X1, with far fewer software issues or glitches. I use multiple indexes, i.e., one for lappy 2TB drive, another for a 4TB external SSD with tons of archived docs. Steadily updated by vendor. Very reasonable price given the power.
Keyword searches allow us to search more than the subject field and broaden our search to the title and abstract fields, for instance, or even the full text if available. This way, if the way we phrase a concept isn't in the subject terms, we still have a good chance of finding what we are looking for.
The traditional ad-supported Google Search would remain available for free. Google, the tech giant synonymous with online search, could be considering a radical change to its business model ...
(1) Background: This five-year systematic review seeks to assess the impact of oral and peri-oral photobiomodulation therapies (PBMTs) on the adjunctive management of deeper tissue biofunction, pathologies related to pain and inflammatory disorders and post-surgical events. (2) Methods: The search engines PubMed, Cochrane, Scopus, ScienceDirect, Google Scholar, EMBASE and EBSCO were used with ...
Voice Engine is a new text-to-speech AI model for creating synthetic voices. OpenAI has said a wide release would be too risky. Along those lines, OpenAI this week announced Voice Engine, a text ...