9.2 DNA Replication
Learning objectives.
- Explain the process of DNA replication
- Explain the importance of telomerase to DNA replication
- Describe mechanisms of DNA repair
When a cell divides, it is important that each daughter cell receives an identical copy of the DNA. This is accomplished by the process of DNA replication. The replication of DNA occurs during the synthesis phase, or S phase, of the cell cycle, before the cell enters mitosis or meiosis.
The elucidation of the structure of the double helix provided a hint as to how DNA is copied. Recall that adenine nucleotides pair with thymine nucleotides, and cytosine with guanine. This means that the two strands are complementary to each other. For example, a strand of DNA with a nucleotide sequence of AGTCATGA will have a complementary strand with the sequence TCAGTACT ( Figure 9.8 ).
Because of the complementarity of the two strands, having one strand means that it is possible to recreate the other strand. This model for replication suggests that the two strands of the double helix separate during replication, and each strand serves as a template from which the new complementary strand is copied ( Figure 9.9 ).
During DNA replication, each of the two strands that make up the double helix serves as a template from which new strands are copied. The new strand will be complementary to the parental or “old” strand. Each new double strand consists of one parental strand and one new daughter strand. This is known as semiconservative replication . When two DNA copies are formed, they have an identical sequence of nucleotide bases and are divided equally into two daughter cells.

DNA Replication in Eukaryotes
Because eukaryotic genomes are very complex, DNA replication is a very complicated process that involves several enzymes and other proteins. It occurs in three main stages: initiation, elongation, and termination.
Recall that eukaryotic DNA is bound to proteins known as histones to form structures called nucleosomes. During initiation, the DNA is made accessible to the proteins and enzymes involved in the replication process. How does the replication machinery know where on the DNA double helix to begin? It turns out that there are specific nucleotide sequences called origins of replication at which replication begins. Certain proteins bind to the origin of replication while an enzyme called helicase unwinds and opens up the DNA helix. As the DNA opens up, Y-shaped structures called replication forks are formed ( Figure 9.10 ). Two replication forks are formed at the origin of replication, and these get extended in both directions as replication proceeds. There are multiple origins of replication on the eukaryotic chromosome, such that replication can occur simultaneously from several places in the genome.
During elongation, an enzyme called DNA polymerase adds DNA nucleotides to the 3' end of the template. Because DNA polymerase can only add new nucleotides at the end of a backbone, a primer sequence, which provides this starting point, is added with complementary RNA nucleotides. This primer is removed later, and the nucleotides are replaced with DNA nucleotides. One strand, which is complementary to the parental DNA strand, is synthesized continuously toward the replication fork so the polymerase can add nucleotides in this direction. This continuously synthesized strand is known as the leading strand . Because DNA polymerase can only synthesize DNA in a 5' to 3' direction, the other new strand is put together in short pieces called Okazaki fragments . The Okazaki fragments each require a primer made of RNA to start the synthesis. The strand with the Okazaki fragments is known as the lagging strand . As synthesis proceeds, an enzyme removes the RNA primer, which is then replaced with DNA nucleotides, and the gaps between fragments are sealed by an enzyme called DNA ligase .
The process of DNA replication can be summarized as follows:
- DNA unwinds at the origin of replication.
- New bases are added to the complementary parental strands. One new strand is made continuously, while the other strand is made in pieces.
- Primers are removed, new DNA nucleotides are put in place of the primers and the backbone is sealed by DNA ligase.
Visual Connection
You isolate a cell strain in which the joining together of Okazaki fragments is impaired and suspect that a mutation has occurred in an enzyme found at the replication fork. Which enzyme is most likely to be mutated?
Telomere Replication
Because eukaryotic chromosomes are linear, DNA replication comes to the end of a line in eukaryotic chromosomes. As you have learned, the DNA polymerase enzyme can add nucleotides in only one direction. In the leading strand, synthesis continues until the end of the chromosome is reached; however, on the lagging strand there is no place for a primer to be made for the DNA fragment to be copied at the end of the chromosome. This presents a problem for the cell because the ends remain unpaired, and over time these ends get progressively shorter as cells continue to divide. The ends of the linear chromosomes are known as telomeres , which have repetitive sequences that do not code for a particular gene. As a consequence, it is telomeres that are shortened with each round of DNA replication instead of genes. For example, in humans, a six base-pair sequence, TTAGGG, is repeated 100 to 1000 times. The discovery of the enzyme telomerase ( Figure 9.11 ) helped in the understanding of how chromosome ends are maintained. The telomerase attaches to the end of the chromosome, and complementary bases to the RNA template are added on the end of the DNA strand. Once the lagging strand template is sufficiently elongated, DNA polymerase can now add nucleotides that are complementary to the ends of the chromosomes. Thus, the ends of the chromosomes are replicated.
Telomerase is typically found to be active in germ cells, adult stem cells, and some cancer cells. For her discovery of telomerase and its action, Elizabeth Blackburn ( Figure 9.12 ) received the Nobel Prize for Medicine and Physiology in 2009. Later research using HeLa cells (obtained from Henrietta Lacks) confirmed that telomerase is present in human cells. And in 2001, researchers including Diane L. Wright found that telomerase is necessary for cells in human embryos to rapidly proliferate.
Telomerase is not active in adult somatic cells. Adult somatic cells that undergo cell division continue to have their telomeres shortened. This essentially means that telomere shortening is associated with aging. In 2010, scientists found that telomerase can reverse some age-related conditions in mice, and this may have potential in regenerative medicine. 1 Telomerase-deficient mice were used in these studies; these mice have tissue atrophy, stem-cell depletion, organ system failure, and impaired tissue injury responses. Telomerase reactivation in these mice caused extension of telomeres, reduced DNA damage, reversed neurodegeneration, and improved functioning of the testes, spleen, and intestines. Thus, telomere reactivation may have potential for treating age-related diseases in humans.
DNA Replication in Prokaryotes
Recall that the prokaryotic chromosome is a circular molecule with a less extensive coiling structure than eukaryotic chromosomes. The eukaryotic chromosome is linear and highly coiled around proteins. While there are many similarities in the DNA replication process, these structural differences necessitate some differences in the DNA replication process in these two life forms.
DNA replication has been extremely well-studied in prokaryotes, primarily because of the small size of the genome and large number of variants available. Escherichia coli has 4.6 million base pairs in a single circular chromosome, and all of it gets replicated in approximately 42 minutes, starting from a single origin of replication and proceeding around the chromosome in both directions. This means that approximately 1000 nucleotides are added per second. The process is much more rapid than in eukaryotes. Table 9.1 summarizes the differences between prokaryotic and eukaryotic replications.
Link to Learning
Click through a tutorial on DNA replication.
DNA polymerase can make mistakes while adding nucleotides. It edits the DNA by proofreading every newly added base. Incorrect bases are removed and replaced by the correct base, and then polymerization continues ( Figure 9.13 a ). Most mistakes are corrected during replication, although when this does not happen, the mismatch repair mechanism is employed. Mismatch repair enzymes recognize the wrongly incorporated base and excise it from the DNA, replacing it with the correct base ( Figure 9.13 b ). In yet another type of repair, nucleotide excision repair , the DNA double strand is unwound and separated, the incorrect bases are removed along with a few bases on the 5' and 3' end, and these are replaced by copying the template with the help of DNA polymerase ( Figure 9.13 c ). Nucleotide excision repair is particularly important in correcting thymine dimers, which are primarily caused by ultraviolet light. In a thymine dimer, two thymine nucleotides adjacent to each other on one strand are covalently bonded to each other rather than their complementary bases. If the dimer is not removed and repaired it will lead to a mutation. Individuals with flaws in their nucleotide excision repair genes show extreme sensitivity to sunlight and develop skin cancers early in life.
Most mistakes are corrected; if they are not, they may result in a mutation —defined as a permanent change in the DNA sequence. Mutations in repair genes may lead to serious consequences like cancer.
- 1 Mariella Jaskelioff, et al., “Telomerase reactivation reverses tissue degeneration in aged telomerase-deficient mice,” Nature , 469 (2011):102–7.
As an Amazon Associate we earn from qualifying purchases.
This book may not be used in the training of large language models or otherwise be ingested into large language models or generative AI offerings without OpenStax's permission.
Want to cite, share, or modify this book? This book uses the Creative Commons Attribution License and you must attribute OpenStax.
Access for free at https://openstax.org/books/concepts-biology/pages/1-introduction
- Authors: Samantha Fowler, Rebecca Roush, James Wise
- Publisher/website: OpenStax
- Book title: Concepts of Biology
- Publication date: Apr 25, 2013
- Location: Houston, Texas
- Book URL: https://openstax.org/books/concepts-biology/pages/1-introduction
- Section URL: https://openstax.org/books/concepts-biology/pages/9-2-dna-replication
© Jan 8, 2024 OpenStax. Textbook content produced by OpenStax is licensed under a Creative Commons Attribution License . The OpenStax name, OpenStax logo, OpenStax book covers, OpenStax CNX name, and OpenStax CNX logo are not subject to the Creative Commons license and may not be reproduced without the prior and express written consent of Rice University.
What is DNA? Everything You Need To Know
- The Albert Team
- Last Updated On: March 1, 2022

What is DNA?
Simply put, DNA (Deoxyribonucleic Acid) is a string of nitrogenous bases (Adenine, Thymine, Guanine, and Cytosine) repeated over and over, and arranged in a seemingly random fashion. Here the genetic code is contained. These bases are connected to each other through chemical bonds. Two complementary strands of DNA are bonded to each other, and are twisted in a helical structure. This extremely long double-stranded twisted string has parts that code for everything in all organisms. Different parts are under different selection pressures.
Below we will outline the history, structure of DNA, the differences and similarities between DNA and RNA . After this, we will then dive into why DNA is so important. Given how important this structure is, we will also talk about how it is replicated ( DNA replication ), packaged, and how these can be exploited or used for DNA fingerprinting.
History of DNA
The discovery of the structure of DNA opened many avenues in the field of biology. In 1962, Watson, Crick, and Wilkins obtained a Nobel Peace Prize for describing it. However, its existence was known of before that. In 1866, Gregor Mendel first hypothesized the existence of inherited entities, now known as genes. Later on (1869), Friedrich Miescher noted an acidic substance in the cell’s nuclei; this substance was referred to as nuclein (we now know this as DNA). Rosalind Franklin captured the famous X-Ray imagery clearly showing its double helical nature. It is her work together with that of the above-mentioned Nobel Laureates that gave us the gold mine (DNA) that has led to advances in all fields of biology; most notably, medicine.
This part of the DNA story is a lot more complex than this, but we will end here for the purpose of this lesson.
DNA Structure
DNA is a nucleic acid, hinted at in the name. Nucleic acids are the building blocks of all living organisms. Nucleotides simply refer to nitrogenous bases, pentose sugar together with the phosphate backbone. Nucleotides are adjacently strung together through a phosphate backbone and are held together with their complements through hydrogen bonds. The number of bonds holding nucleotides from the complementary strands depends on the type of nitrogenous base the nucleotide contains.

A nitrogenous base is a molecule with nitrogen that possesses the chemical properties of a base. These are crucial to the DNA as they define the genetic code (they are the code!). The pentose sugar connects the nitrogenous base to the phosphate backbone. There are four kinds of nitrogenous bases; namely, thymine (T), cytosine (C), adenine (A) and guanine (G). Guanine and adenine are purines while thymine and cytosine are pyrimidines . Purines have two rings (see adenine on figure 2) while pyrimidines have one ring. For the structure of the DNA to be able to twist and be packaged accordingly without bulging and the opposite bases to be able to pair up, a purine has to fit in a pyrimidine. To this end, the purine guanine pairs with the pyrimidine cytosine and the purine adenine pairs with the pyrimidine thymine.

Differences and Similarities between DNA and RNA
Both molecules are nucleic acids made up of nucleotides, supported by a phosphate backbone. They are both major players in the central dogma. RNA is transcribed from the DNA to make proteins. DNA carries all the information needed for DNA replication and transfer new information to new cells.
They are involved in the maintenance, replication, and expression of hereditary information. DNA holds the key to heredity. RNA helps DNA unlock this code and show us what this code is capable of achieving. Together these molecules ensure that the DNA is replicated, the code is translated, expressed and that things go where they should go.
DNA and RNA work hand in hand in biology. It is rare that one can speak of the one without bringing up the other. Simply put, they are connected by the central dogma. The central dogma is the process of DNA transcription and translation for the purpose of protein synthesis which then perform a multitude of tasks in organisms. Different types of proteins guide the gene expression. Therefore, even though the DNA is the same throughout- different things happen at different part of the body. In addition to this, it also tells stem cells what to differentiate to. This is due to strict regulatory mechanisms in place to control gene expression.
Both DNA and RNA have a negative backbone (because of the phosphate group). They both have four nucleotides each, three of which they share (Guanine, Cytosine, and Adenine); with one significant difference, DNA has Thymine while RNA has Uracil. DNA is double-stranded while RNA is single-stranded. Last but not least, DNA is found in the nucleus while RNA resides both in the nucleus and the cytoplasm. DNA is long-lived while RNA is regenerated with each reaction.
They are both central to cell function.
DNA Packaging
How does DNA fit into the cell? Consider this; each and every one of your cells contains approximately 6 billion base pairs of DNA, with each base pair being 0.34 nanometers long. This works out to about 2 meters of DNA per diploid cell! If the DNA sequence is so long how does the nucleus manage to house the DNA and many other components necessary for the functioning of the cell? The answer is very simple, through condensing and packaging.
DNA is packaged with the help of histone proteins. Histones are small proteins with basic, positively charged amino acids; namely, arginine and lysine. They bind and neutralize the negatively charged DNA (because of the negatively charged phosphate backbone). It takes five types of histones to package DNA; H1, H2A, H2B, H3, and H4. Core histones (H2A, H2B, H3, and H4) with DNA coiled around them are referred to as nucleosomes. It takes two of each of the core histones to make up a nucleosome. Per nucleosome an H1 histone sits outside the coil holding the nucleosome intact. The nucleosome together with histone H1 are collectively referred to as chromatosome. The nucleosomes are condensed to fibers called chromatin. Bigger loops of tightly packed chromatin then make chromosomes.

Keeping DNA in a coiled and inaccessible state ensures DNA safety. As you can imagine, with this much coiling, twisting and packing the DNA is not accessible for transcription and/ or replication. This becomes redundant if the DNA cannot perform its functions. For DNA to perform its functions it needs to be unpacked and made accessible again. It is in this state that DNA can be replicated in order to, amongst other things; accommodate organism’s growth and maturity through cell division facilitated by DNA replication to ensure there is sufficient DNA in every cell.
DNA Replication
To understand DNA replication you will need to keep the following in mind:
– Replication duplicates the genetic information; this means you end up with a collection of identical DNA strands.
– The rules of DNA replication (A to T; G to C) govern replication.
– Each of the two strands DNA serves as a template of the new strand.
-DNA replication is essential for cell division.
DNA replication takes place in 5’®3’ direction. This means that bases will be added from left to right direction. The template strand will guide this process by telling the new strand which base comes next, this will go on until the new strand is complete and the DNA will once again be double-stranded. Both strands of the old DNA will serve as templates of two new strands. This means that at the end there will be two double-stranded DNAs, identical to each other. This way once cell division occurs, the new cells will contain identical information as the rest of the body. A slew of proteins oversee the whole process make sure things happen at the right time and in the right way.

Due to the complementary nature of DNA, one strand is in the 5’®3’ direction while the other is in the 3’®5’ direction. The fore is referred to as the lagging strand while the latter is called the leading strand.
In preparation for DNA replication, the double-strand unwinds and separate to form replication forks. Each template strand attracts the complements to the now exposed bases; this happens in a stepwise fashion. The back-bone solidifies and the DNA rewinds. This is a very simplified version of the process. What follows is the detailed version with the enzymes involved to guide the process.
An enzyme called helicase unwinds the template strands. The single strand binding proteins then stabilize the template strands in preparation for the replication, it holds it open until the end of the replication process. DNA polymerase III synthesizes nucleotides onto the leading end in the 5’®3′ direction.
The replication directed by the lagging strand, however, is a little more complicated. Helicase can only synthesize in the 5’®3′ direction, this poses a problem where the only available direction is 3’®5’. To get around this, Okazaki fragments are synthesized. Primase, as the name suggests, primes the synthesis of the new strand through synthesizing RNA primers to direct the addition of Okazaki fragments. Okazaki fragments are added onto the lagging strand by DNA ligase bonding the 3’ end to the 5’ of the previous fragment. The primers that prime the addition of the Okazaki fragments are then removed by DNA polymerase I and replaced by DNA bases. At the end of the process after the removal of the last primer there is an exposed 3’ end. DNA polymerase III completes the synthesis of the new strand, by adding DNA nucleotides at the end of the new strand. Nuclease provides proofreading services, correcting mistakes made during replication. As you can imagine, there will be a very tight coil at the end of the replication fork. Topoisomerase fixes this problem by making a small nick that releases the tension build up.
DNA Comparison and DNA Fingerprinting
DNA information has been used in comparative studies in order to understand not just where we stand as a species in the animal kingdom but where other species fit and how their genetic make-up influences their way of living. DNA fingerprinting, also called DNA profiling, refers to a technique of using a collection of individual specific regions of their genome. This is based on the idea that different combinations of various regions of the genome are very unlikely to be shared across individual. So, for example even though some of these sections can be shared between family members it is highly unlikely that they would all be identical between family members.
Different parts of the DNA code are under stricter selection pressures. This fact is one of the most exploited properties of the genome when studying organisms at different levels (e.g. population level, species level, genus level, etc.). Gene regions such as those coding for the internal transcriber region of the ribosome are under somewhat strict controls, and these evolve relatively slow. These, can, therefore, be used to study variations at the species level (species level marker). Other markers are under very little to no selection (neutral selection) and therefore evolve more freely, for example, simple sequence repeats such as micro satellites. These are more informative and can be used to study population dynamics. Some areas evolve so fast that they can be used to identify and different between individuals in a population to differentiating between individuals born of the same parents.

Using regions in the nuclear DNA to identify individuals, species or higher taxa is what we refer to as DNA bar coding. To study population dynamics markers such micro-satellites prove useful as their polymorphic profile can tell us a lot about how often intra and inter-breeding occur within and across populations. It can also give clues to infer modes of dispersal. To study evolutionary processes and phylogenetic relationships slow evolving markers such as mitochondrial DNA can be used. These can tell us where species sit in the bigger picture.
There are a large variety of fields in biology that exist because of the ability to study and manipulate the DNA code. These include fields such as genetic engineering; this is how you can enjoy summer fruits in winter. Other fields include gene therapy; here biologists use the knowledge of the genome to manipulate specific parts of the genome to remove lethal variants of some genes. The availability of techniques such as DNA fingerprinting also helps to better understand genetic diseases, and with the help of research such as that into CRISPR-CAS9, hopefully, enable us to cure diseases such as cancer.
Is DNA Important?
The simple answer is, yes, very much so. We hope at this point you agree with this answer. Just think of all the things DNA code for (pretty much everything). Now imagine life without them. What is left? Is any of it biotic?
DNA is what makes you special, alive and functional. Without DNA you would not exist. Everything you have, the thing you consider your best feature would not exist without DNA. DNA directs cell function. If there was no DNA, cell division would not happen—therefore no differentiation, this means you would not exist neither would your pet. Even though DNA is not solely responsible for life as we know it is still arguably the most important factor. Other factors include the environment and experience. DNA is important for many reasons—so many in fact that we cannot list them all. To name a few it is important in the fields of genealogy, forensic science, agriculture, and virology.
In conclusion, DNA forms the basis for life. The discovery of the DNA structure has led to major strides in research, medicine, agriculture and many other fields. Given how important this structure is to our existence, it only makes sense that its description has affected so many areas of our lives. We hope at this point you have as much appreciation as we do for what DNA is and can do, how is differs from RNA, how many lives it has revolutionized and DNA fingerprinting. At this point, you should also have an appreciation for what DNA is in biology and what it means for this field.
Featured Image Source
Let’s put everything into practice. Try this Biology practice question:
Looking for looking for more biology practice.
Check out our other articles on Biology .
You can also find thousands of practice questions on Albert.io. Albert.io lets you customize your learning experience to target practice where you need the most help. We’ll give you challenging practice questions to help you achieve mastery in Biology.
Start practicing here .
Are you a teacher or administrator interested in boosting Biology student outcomes?
Learn more about our school licenses here .
Interested in a school license?
Popular posts.

AP® Score Calculators
Simulate how different MCQ and FRQ scores translate into AP® scores

AP® Review Guides
The ultimate review guides for AP® subjects to help you plan and structure your prep.

Core Subject Review Guides
Review the most important topics in Physics and Algebra 1 .
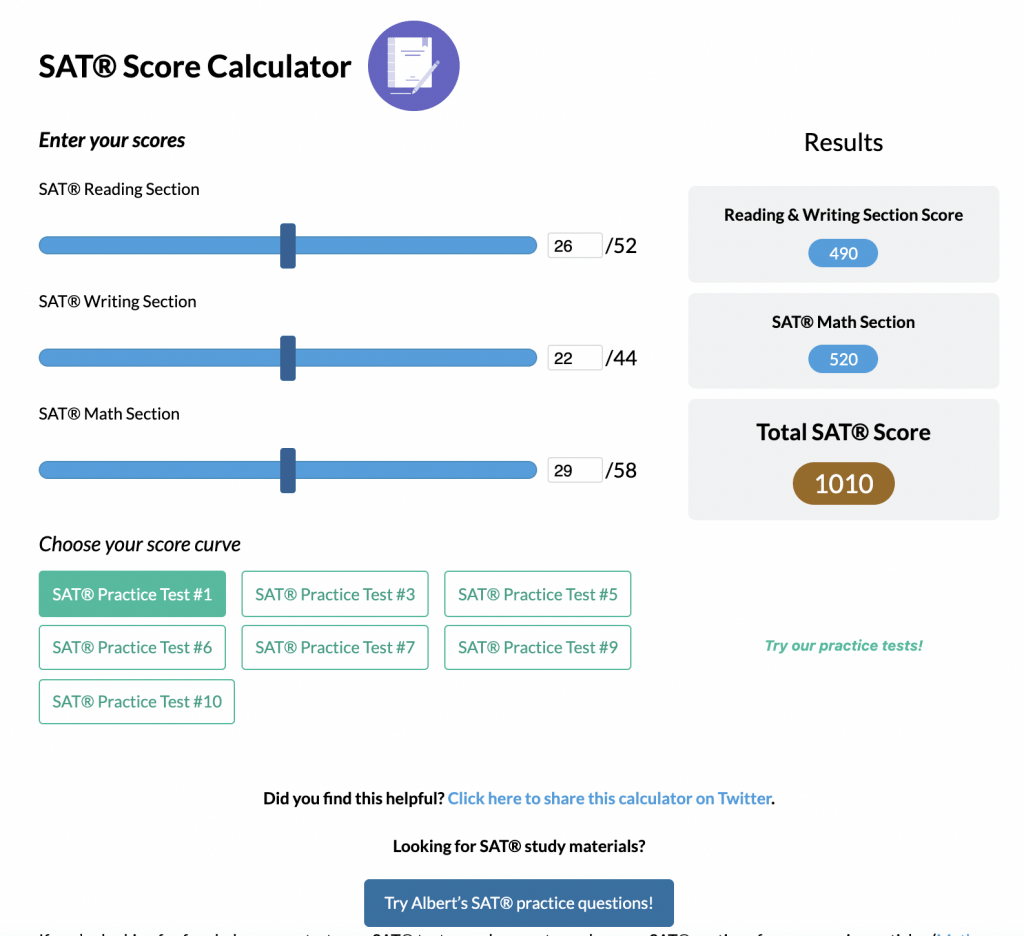
SAT® Score Calculator
See how scores on each section impacts your overall SAT® score
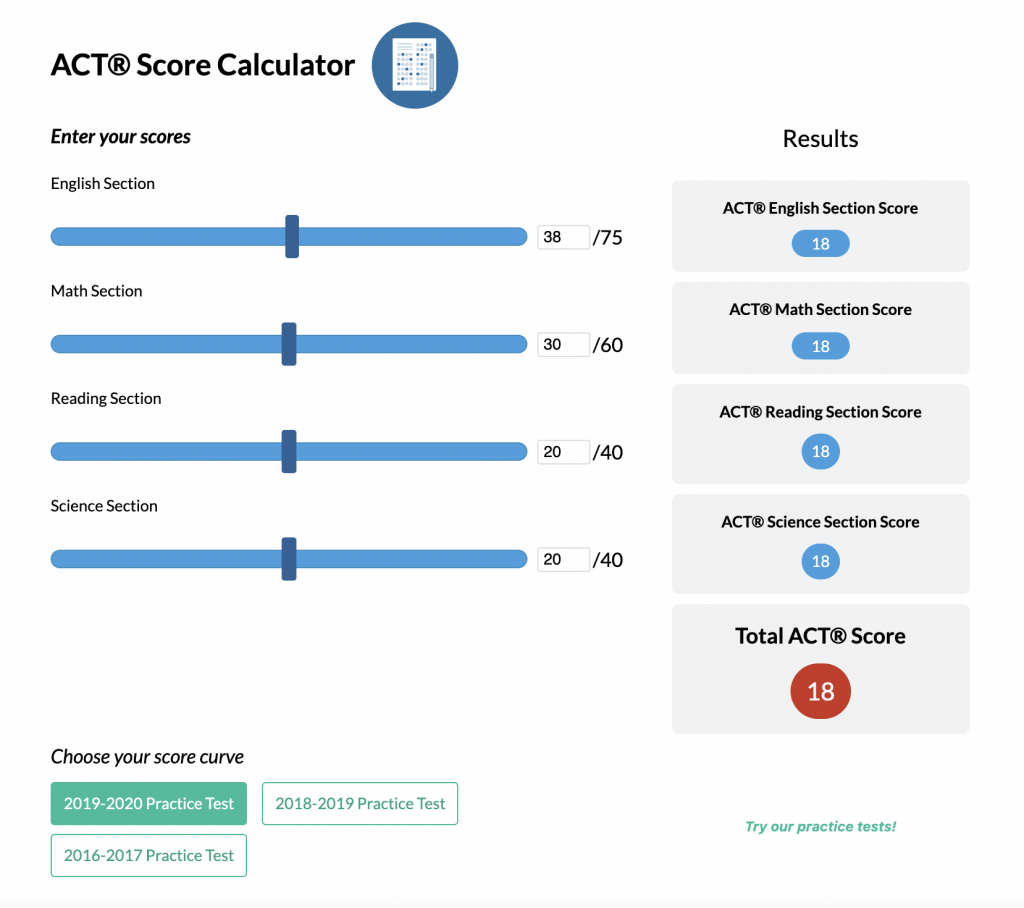
ACT® Score Calculator
See how scores on each section impacts your overall ACT® score
Grammar Review Hub
Comprehensive review of grammar skills

AP® Posters
Download updated posters summarizing the main topics and structure for each AP® exam.
Interested in a school license?

Bring Albert to your school and empower all teachers with the world's best question bank for: ➜ SAT® & ACT® ➜ AP® ➜ ELA, Math, Science, & Social Studies aligned to state standards ➜ State assessments Options for teachers, schools, and districts.
If you're seeing this message, it means we're having trouble loading external resources on our website.
If you're behind a web filter, please make sure that the domains *.kastatic.org and *.kasandbox.org are unblocked.
To log in and use all the features of Khan Academy, please enable JavaScript in your browser.
Biology library
Course: biology library > unit 17.
- DNA replication and RNA transcription and translation
- Leading and lagging strands in DNA replication
- Speed and precision of DNA replication
- Molecular structure of DNA
- Molecular mechanism of DNA replication
Mode of DNA replication: Meselson-Stahl experiment
- DNA proofreading and repair
- Telomeres and telomerase
- DNA replication
Key points:
- There were three models for how organisms might replicate their DNA: semi-conservative, conservative, and dispersive.
- The semi-conservative model, in which each strand of DNA serves as a template to make a new, complementary strand, seemed most likely based on DNA's structure.
- The models were tested by Meselson and Stahl, who labeled the DNA of bacteria across generations using isotopes of nitrogen.
- From the patterns of DNA labeling they saw, Meselson and Stahl confirmed that DNA is replicated semi-conservatively.
Mode of DNA replication
The three models for dna replication.
- Conservative. Replication produces one helix made entirely of old DNA and one helix made entirely of new DNA.
- Semi-conservative. Replication produces two helices that contain one old and one new DNA strand.
- Dispersive. Replication produces two helices in which the individual strands are patchworks of old and new DNA.
- Semi-conservative replication. In this model, the two strands of DNA unwind from each other, and each acts as a template for synthesis of a new, complementary strand. This results in two DNA molecules with one original strand and one new strand.
- Conservative replication. In this model, DNA replication results in one molecule that consists of both original DNA strands (identical to the original DNA molecule) and another molecule that consists of two new strands (with exactly the same sequences as the original molecule).
- Dispersive replication. In the dispersive model, DNA replication results in two DNA molecules that are mixtures, or “hybrids,” of parental and daughter DNA. In this model, each individual strand is a patchwork of original and new DNA.
Meselson and Stahl cracked the puzzle
The meselson-stahl experiment, results of the experiment, generation 0, generation 1, generation 2.
- Generation 0 (see above). 100% of DNA in nitrogen-15 band.
- Generation 1. 100% of DNA in a band intermediate in position between nitrogen-14 and nitrogen-15 bands.
- Generation 2. 50% of DNA in a band intermediate in position between nitrogen-14 and nitrogen-15 bands. 50% of DNA in nitrogen-14 band.
- Generation 3. 25% of DNA in a band intermediate in position between nitrogen-14 and nitrogen-15 bands. 75% of DNA in nitrogen-14 band.
- Generation 4. 12% of DNA in a band intermediate in position between nitrogen-14 and nitrogen-15 bands. 88% of DNA in nitrogen-14 band.
Generations 3 and 4
Attribution:, works cited:.
- Watson, J. D. and Crick, F. H. C. (1953). A structure for deoxyribose nucleic acid. Nature , 171 (4356), 737-738. Retrieved from http://www.nature.com/nature/dna50/watsoncrick.pdf .
- Reece, J. B., Urry, L. A., Cain, M. L., Wasserman, S. A., Minorsky, P. V., and Jackson, R. B. (2011). The basic principle: Base pairing to a template strand. In Campbell biology (10th ed.). San Francisco, CA: Pearson, 318-319.
- American Institute of Biological Sciences. (2003). Biology's most beautiful. http://www.aibs.org/about-aibs/030712_take_the_bioscience_challenge.html .
- Watson, J. D., and Crick, F. H. C. (1953). Genetical implications of the structure of deoxyribonucleic acid. Nature , 171 , 740-741.
- Davis, T. H. (2004). Meselson and Stahl: The art of DNA replication. PNAS , 101 (52), 17895-17896. http://dx.doi.org/10.1073/pnas.0407540101 .
References:
Want to join the conversation.
- Upvote Button navigates to signup page
- Downvote Button navigates to signup page
- Flag Button navigates to signup page

DNA Replication as a Semiconservative Process Essay
The process of DNA replication has been studied extensively as the pathway to understanding the processes of inheritance and the possible platform for addressing a range of health issues occurring as a result of DNA mutations.
However, the subject matter is still plagued by grey areas that require further analysis, the very properties of the process being one of the core issues of debating. Specifically, whether DNA replication can be deemed as semiconservative remains largely an unanswered question (Georgia Highlands College, n.d.). I believe that, despite the lack of certainty regarding the problem under analysis, it would be reasonable to believe that DNA replication is semiconservative since it is consistent with the fact that, during the reproduction process, DNS is separated into two bands.
The statement concerning DNA replication being a semiconservative process that leads to the development of two separate strands of DNA material has been supported by a vast range of evidence. Recent experiments point to the correctness of the semiconservative framework as the most legitimate theory that allows describing the process of DNA replication in the greatest detail possible (Georgia Highlands College, n.d.). In order to concede that the process of DNA replication is semiconservative, one should take a closer look at the outcomes of the experiment performed.
Since the test performed by Meselson and Stahl showed that the amount of the DNA material was equal in two daughter cells, yet the density thereof was different, the presence of semiconservative properties in DNA replication can be regarded as proven. By asserting that the observed tendency could be found in not only the strands of E.coli but also in other species, Meselson and Stahl made it evident that the DNA replication did, in fact, show semiconservative properties (Georgia Highlands College, n.d.). Thus, I insist that the existing evidence points to the DNA replication process being semiconservative.
The described outcomes of the experiment also lead to a vast range of conclusions concerning the nature and outcomes of DNA replications in different species. By defining DNA replication as semiconservative, the researchers made it evident that every double helix axis in the DNA structure built with the help of DNA polymerases leads to the creation of an entirely new strand that acts as complementary (Georgia Highlands College, n.d.).
It should also be borne in mind that the specified characteristic of the DNA structure makes it possible for the new strand, which is also known as the leading one, to emerge as a continuous piece, whereas the complementary one, or the lagging strand, occurs as a combination of smaller pieces (Georgia Highlands College, n.d.). By applying the notion of the DNA replication process being semiconservative, one can explain the observed changes within the DNA framework and provide the foundation for the further analysis of the subject matter.
Indeed, the results of the experiment described above cannot be deemed as consistent with the theory of dispersive replication, which has been offered as the alternative to the semiconservative framework. Using isotopes of nitrogen as the tools for labeling the DNA of the studied bacteria, Meselson and Stahl staged an experiment in the course of which the nature of the DNA replication process and the basis for its implementation were studied (Georgia Highlands College, n.d.). The semiconservative assumption made by the scientists implied that, in the process of replication, entirely new strands of DNA were produced with the help of the ones that were already present in the cells of the bacteria under analysis.
During the experiment, it was discovered that each of the nitrogenous bases presented in the DNA structure is only capable of connecting to its corresponding complementary partner. For adenine, the process of pairing occurs with thymine, whereas cytosine is connected to guanine in the process (Georgia Highlands College, n.d.). The resulting replication process, thus, takes place due to the combination of the helicase and DNA polymerase procedures (Georgia Highlands College, n.d.). Therefore, I strongly believe that the principle of DNA replication as the notion based on the semiconservative framework seems to be quite valid, given the vast amount of supportive evidence that has been collected.
Based on the outcomes of the Meselson–Stahl experiment, during which the DNA showed a strong propensity toward splitting into two distinct brands, the assumption that the DNA process is semiconservative can be regarded as confirmed. Even though it could be alleged that the current research has been erroneous and that the process of DNA replication may involve different processes and be based on an entirely different principle, the veracity of the identified statement is quite feeble. Thus, the stages of DNA replication can be seen as the semiconservative process. The presence of a synthesized strand along with the preexisting template one has proven to be the most sensible way of looking at the DNA replication stage.
Georgia Highlands College. (n.d.). Chapter 14 – DNA structure and function . Web.
- Chicago (A-D)
- Chicago (N-B)
IvyPanda. (2021, June 2). DNA Replication as a Semiconservative Process. https://ivypanda.com/essays/dna-replication-as-a-semiconservative-process/
"DNA Replication as a Semiconservative Process." IvyPanda , 2 June 2021, ivypanda.com/essays/dna-replication-as-a-semiconservative-process/.
IvyPanda . (2021) 'DNA Replication as a Semiconservative Process'. 2 June.
IvyPanda . 2021. "DNA Replication as a Semiconservative Process." June 2, 2021. https://ivypanda.com/essays/dna-replication-as-a-semiconservative-process/.
1. IvyPanda . "DNA Replication as a Semiconservative Process." June 2, 2021. https://ivypanda.com/essays/dna-replication-as-a-semiconservative-process/.
Bibliography
IvyPanda . "DNA Replication as a Semiconservative Process." June 2, 2021. https://ivypanda.com/essays/dna-replication-as-a-semiconservative-process/.
- Imitation of Life' by Stahl and Sirk Movies Compare
- The Movie “Imitation of Life” by John Stahl
- Enzyme Specificity and Regulation
- Molecular Components of the DNA Molecule
- Need for Good Leadership in Organizations
- Structure of Deoxyribonucleic Acid
- Conceptual Structure of the Chemical Revolution
- Interesting and Relevant Applications of DNA Technology
- Infectious Bacterial Identification From DNA Sequencing
- Database Replication Among Geographically Remote Sites
- Plasmids, Their Characteristics and Role in Genetics
- The Dangers of Genetic Engineering and the Issue of Human Genes’ Modification
- "How One Cell Gives Rise to an Entire Body" by Pennisi
- Sickle Cell Disease and Scientific Inventions
- Gene Therapy: Risks and Benefits

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Portland Press Opt2Pay
Mitochondrial DNA replication in mammalian cells: overview of the pathway
Maria falkenberg.
Department of Medical Biochemistry and Cell Biology, University of Gothenburg, P.O. Box 440, 405 30 Gothenburg, Sweden
Mammalian mitochondria contain multiple copies of a circular, double-stranded DNA genome and a dedicated DNA replication machinery is required for its maintenance. Many disease-causing mutations affect mitochondrial replication factors and a detailed understanding of the replication process may help to explain the pathogenic mechanisms underlying a number of mitochondrial diseases. We here give a brief overview of DNA replication in mammalian mitochondria, describing our current understanding of this process and some unanswered questions remaining.
Introduction
Mitochondrial DNA (mtDNA) is a double-stranded molecule of 16.6 kb ( Figure 1 , lower panel). The two strands of mtDNA differ in their base composition, with one being rich in guanines, making it possible to separate a heavy (H) and a light (L) strand by density centrifugation in alkaline CsCl 2 gradients [ 1 ]. The mtDNA contains one longer noncoding region (NCR) also referred to as the control region. In the NCR, there are promoters for polycistronic transcription, one for each mtDNA strand; the light strand promoter (LSP) and the heavy strand promoter (HSP). The NCR also harbors the origin for H-strand DNA replication (O H ). A second origin for L-strand DNA replication (O L ) is located outside the NCR, within a tRNA cluster approximately 11,000 bp downstream of O H .

The genome encodes for 13 mRNA (green), 22 tRNA (violet), and 2 rRNA (pale blue) molecules. There is also a major noncoding region (NCR), which is shown enlarged at the top. The major NCR contains the heavy strand promoter (HSP), the light strand promoter (LSP), three conserved sequence boxes (CSB1-3, orange), the H-strand origin of replication (O H ), and the termination-associated sequence (TAS, yellow). The triple-stranded displacement-loop (D-loop) structure is formed by premature termination of nascent H-strand DNA synthesis at TAS. The short H-strand replication product formed in this manner is termed 7S DNA. A minor NCR, located approximately 11,000 bp downstream of O H , contains the L-strand origin of replication (O L ).
mtDNA replication factors
Mammalian mtDNA is replicated by proteins distinct from those used for nuclear DNA replication and many are related to replication factors identified in bacteriophages [ 2 ]. DNA polymerase γ (POLγ) is the replicative polymerase in mitochondria. In human cells, POLγ is a heterotrimer with one catalytic subunit (POLγA) and two accessory subunits (POLγB) [ 3–5 ]. Mouse knockouts for POLγA and POLγB have revealed that both factors are essential for embryonic development [ 6 , 7 ]. At least four additional polymerases (PrimPol, DNA polymerase β, DNA polymerase θ, and DNA polymerase ζ) have been reported to play a role mitochondria [ 8–11 ]. These polymerases are not essential for mtDNA maintenance and none of them can substitute for POLγ. Most likely they are involved in mtDNA repair, but the exact function of these additional polymerases in mtDNA maintenance needs to be further elucidated (reviewed in [ 12 ]).
POLγA belongs to the family A DNA polymerases and contains a 3′–5′ exonuclease domain that acts to proofread the newly synthesized DNA strand [ 3 ]. POLγ is a highly accurate DNA polymerase with a frequency of misincorporation lower than 1 × 10 −6 [ 13 ]. The accessory POLγB subunit enhances interactions with the DNA template and increases both the catalytic activity and the processivity of POLγA [ 14–16 ]. POLγ cannot use double-stranded DNA as a template and a DNA helicase is therefore required at the mitochondrial replication fork [ 17 ]. The DNA helicase TWINKLE is homologous to the T7 phage gene 4 protein [ 18 ] and during mtDNA replication, TWINKLE travels in front of POLγ, unwinding the double-stranded DNA template. TWINKLE forms a hexamer and requires a fork structure (a single-stranded 5′-DNA loading site and a short 3′-tail) to load and initiate unwinding [ 18–20 ]. Mitochondrial single-stranded DNA-binding protein (mtSSB) binds to the formed ssDNA, protects it against nucleases, and prevents secondary structure formation [ 21 , 22 ]. mtSSB enhances mtDNA synthesis by stimulating TWINKLE’s helicase activity as well as increasing the processivity of POLγ [ 17 , 19 , 23 ].
The mode of mtDNA replication
A model for mtDNA replication was presented already in 1972 by Vinograd and co-workers ( Figure 2 ) [ 24 ]. According their strand displacement model, DNA synthesis is continuous on both the H- and L-strand [ 25 ]. There is a dedicated origin for each strand, O H and O L . First, replication is initiated at O H and DNA synthesis then proceeds to produce a new H-strand. During the initial phase, there is no simultaneous L-strand synthesis and mtSSB covers the displaced, parental H-strand [ 26 ]. By binding to single-stranded DNA, mtSSB prevents the mitochondrial RNA polymerase (POLRMT) from initiating random RNA synthesis on the displaced strand [ 27 ]. When the replication fork has progressed about two-thirds of the genome, it passes the second origin of replication, O L . When exposed in its single-stranded conformation, the parental H-strand at O L folds into a stem–loop structure [ 28 ]. The stem efficiently blocks mtSSB from binding and a short stretch of single-stranded DNA in the loop region therefore remains accessible, allowing POLRMT to initiate RNA synthesis [ 26 , 29 ]. POLRMT is not processive on a single-stranded DNA templates [ 27 ]. Already after about 25 nt, it is replaced by POLγ and L-strand DNA synthesis is initiated [ 30 ]. From this point, H- and L-strand synthesis proceeds continuously until the two strands have reached full circle. Replication of the two strands is linked, since H-strand synthesis is required for initiation of L-strand synthesis. The structure and the sequence requirement for mammalian O L has been studied both in vivo and in vitro , demonstrating that a functional human O L must include a stable double-stranded stem region with pyrimidine-rich template strand and a single-stranded loop of at least 10 nt [ 31 ].

Mitochondrial DNA replication is initiated at O H and proceeds unidirectionally to produce the full-length nascent H-strand. mtSSB binds and protects the exposed, parental H-strand. When the replisome passes O L , a stem–loop structure is formed that blocks mtSSB binding, presenting a single-stranded loop-region from which POLRMT can initiate primer synthesis. The transition to L-strand DNA synthesis takes place after about 25 nt, when POLγ replaces POLRMT at the 3′-end of the primer. Synthesis of the two strands proceeds in a continuous manner until two full, double-stranded DNA molecules have been formed.
It should be noted that some aspects of the strand-displacement model have been questioned. For instance, studies have suggested that processed RNA molecules hybridize to the single-stranded H-strand and function as a provisional lagging strand, which is replaced by DNA during later stages of mtDNA replication [ 32 ]. This so-called RITOLS model implicates that processed transcripts are successively hybridized to the paternal H-strand as the replication fork advances, but the enzymatic machinery required for this process has not been identified [ 33 ]. Arguing against the RITOLS model, single-stranded DNA binding proteins are used to stabilize single-stranded DNA intermediates during DNA replication in all three major branches of life. In mitochondria, there are at least 500 mtSSB tetramers available per mtDNA molecule. Since each tetramer binds 59 nt, the levels of mtSSB are sufficient to cover the entire parental H-strand during mtDNA synthesis [ 26 , 34 ]. In addition, strand-specific chromatin immunoprecipitation has revealed that mtSSB exclusively covers the parental H-strand during mtDNA replication in vivo . The occupancy profile displays a distinct pattern, with the highest levels of mtSSB close to OriH, followed by a gradual decline toward OriL. The pattern is thus as would be predicted if mtSSB functions to stabilize the single-stranded, paternal H-strand during strand-displacement DNA replication [ 26 ]. Yet another problem for the RITOLS model is the presence of RNASEH1 in mitochondria. This enzyme efficiently removes RNA–DNA hybrids, an activity that is difficult to reconcile with processed RNA molecules stably binding to long stretches of single-stranded DNA during mtDNA replication [ 35 ].
Finally, there have been reports suggesting that under certain conditions, strand-coupled replication may function as a backup replication mode in mammalian mitochondria [ 36 , 37 ]. The molecular mechanisms underlying this type of replication have not been elucidated.
Curiously, not all replication events initiated at O H continue to full circle. Instead, 95% are terminated already after about 650 nt at the termination associated sequences (TAS) [ 38 , 39 ]. The short DNA fragment formed in this way, 7S DNA, remains bound to the parental L-strand, while the parental H-strand is displaced ( Figure 1 , top panel). As a result, a triple-stranded displacement loop structure, a D-loop, is formed. The functional importance of the D-loop structure is unclear and how replication is terminated at TAS is also not known [ 40 , 41 ]. It appears however that termination at TAS is a regulated event, providing a switch between abortive and genome length mtDNA replication [ 42 ]. In support of this notion, in vivo occupation analysis revealed that POLγ under normal conditions stalls at the 3′-end of the D-loop, whereas TWINKLE occupancy is low in this region. When mtDNA is depleted, the situation changes and TWINKLE occupancy increases and at the same time 7S DNA levels are decreased. These data have been interpreted as evidence for TWINKLE reloading in response to increased demand for mtDNA replication [ 42 ]. Binding of the helicase to the 3′-end of 7S DNA would allow the stalled POLγ to continue replication of 7S DNA to full circle. The model receives support from mouse genetic experiments, demonstrating that TWINKLE is important for mtDNA copy number control. Increased or decreased levels of TWINKLE correlate nicely with mtDNA levels [ 43–46 ]. It is thus possible that mtDNA replication is regulated at the level of pretermination rather than initiation. The switch may fine-tune the mtDNA copy number in response to cellular demands.
Interestingly, two closely related 15 nt and evolutionary conserved palindromic sequence motifs (ATGN 9 CAT) are located on each side of the D-loop region. One motif is located just upstream of the 5′-end of the 7S DNA, where it forms a part of conserved sequence box 1, CSB1. The second motif, core-TAS, is located within the TAS region, just downstream of the 3′-end of 7S DNA ( Figure 1 , top panel) [ 42 ]. The physiological role of these motifs remains unclear, but sequence-specific DNA binding proteins often recognize and bind palindromic sequences. In support of this notion, there are published in organello footprints located to the TAS region [ 47 ], but despite substantial efforts in different laboratories, a TAS-binding protein has so far not been identified. It is possible that the proteins binding to CSB1, core-TAS, and other regions within TAS are difficult to purify by traditional methods. Perhaps the missing protein is membrane bound and difficult to retain in solution during chromatography. Alternatively, binding could be a regulated event, requiring precise redox conditions or nucleotide concentrations. Finally, it cannot be excluded that secondary structures in mtDNA may play a role, e.g. stem–loops or G-quadruplexes, which could also contribute to the observed in vivo DNA footprints.
Initiation of mtDNA replication at O H
We know that POLRMT forms the primers necessary to initiate H-strand synthesis O H [ 48–51 ]. Transcripts initiated at LSP provide RNA 3′-ends from which POLγ can initiate DNA synthesis. In human mitochondria, there are multiple transitions points (RNA-to-DNA transitions) located downstream of LSP, clustering around two conserved sequence motifs, CSB3 and CSB2 ( Figure 1 , top panel) [ 52–54 ]. These conserved sequence elements are guanine-rich and during transcription, a G-quadruplex structure can form between nascent RNA and the nontemplate DNA strand at CSB2. In this manner, the nascent transcript is anchored to mtDNA, forming an R-loop structure [ 30 , 55 ]. The G-quadruplex structure also causes premature transcription termination at sites roughly corresponding to RNA to DNA transition sites mapped in the CSB2-region [ 56 ]. Based on these observations, it was hypothesized that sequence-dependent transcription termination may be responsible for primer formation at O H [ 54–56 ]. The transcription elongation factor TEFM, strongly reduces transcription termination and R-loop formation at CSB2, leading to the suggestion that active TEFM may influence the ratio between primer formation and full-length, productive transcription [ 57 , 58 ]. Arguing against this idea, knockdown of TEFM in cells only has very limited effects on mtDNA copy number and mitochondrial replication intermediates [ 59 ]. In addition, there are no direct experimental evidence demonstrating that R-loop-forming, prematurely terminated transcripts can be directly used by POLγ to initiate DNA synthesis. Further experiments are clearly needed to define the precise role of R-loops and TEFM in replication initiation.
The mechanisms of DNA replication initiation at O H may resemble those previously described for initiation of DNA replication in the E. coli plasmid ColE1. In the plasmid, a transcript denoted RNAII associates with the template strand, forming an R-loop that is used to prime DNA synthesis [ 60 , 61 ]. Furthermore, the ColE1 origin of replication is situated downstream of a guanine-rich stretch that is essential for both replication initiation and R-loop formation [ 61 , 62 ]. In ColE1, the R-loop is cleaved by RNase H, before it is used to prime DNA synthesis. If the mitochondrial RNASEH1 plays a similar role in mammalian cells remains to be determined [ 63 , 64 ].
Termination of mtDNA replication
When POLγ has completed synthesis, the newly formed DNA strands are ligated by DNA ligase III [ 65 , 66 ]. To allow for efficient ligation, the 5′- and 3′-ends of the nascent DNA ends must be juxtaposed, which means that the RNA primers used to initiate mtDNA synthesis must first be removed [ 67 ]. A likely candidate for primer removal is RNASEH1, inasmuch as RNA primers are retained in the mitochondrial origin regions in mouse embryonic fibroblasts lacking Rnaseh1 and there is a loss of mtDNA in Rnaseh1 knockout mice [ 35 , 68 ].
After completing a full circle-replication, POLγ encounters the 5′-end of the nascent full-length mtDNA strand it has just produced. At this point, POLγ initiates successive cycles of polymerization and 3′–5′ exonuclease degradation at the nick [ 67 , 69 ]. This process, idling, is required for proper ligation. POLγ lacking exonuclease activity is unable to idle and instead continues DNA synthesis into the dsDNA region past the 5′-end, thereby creating a flap-structure that cannot be ligated. Failure to create ligatable DNA ends may explain why mice with exonuclease-deficient POLγ display strand-specific nicks at O H [ 67 , 70 ].
Interestingly, there is a major 5′-end of nascent DNA located approximately 100 bp further downstream of the identified RNA-to-DNA transitions sites. Historically, this site (position 191 in human mtDNA) has been seen as a part of O H , but how this 5′-end is generated is not clear [ 25 ]. Although initially identified as a start site for mtDNA replication, the free 5′-end at position 191 may be generated in other ways. For instance, the nascent H-strand may undergo considerable 5′-end processing during primer removal, removing not only the RNA primer, but also ∼100 nt of downstream DNA [ 42 ]. In this way, the site for RNA-to-DNA transition would be separated from the site of nascent H-strand ligation at the end of replication. A possible candidate for this effect is the mitochondrial genome maintenance exonuclease 1 (MGME1), a mitochondrial RecB-type exonuclease belonging to the PD-(D/E)XK nuclease superfamily [ 71 , 72 ]. In vitro analysis revealed that MGME1 cuts both ssDNA and DNA flap substrates. Human cells lacking active MGME1 display impaired ligation at O H and the formation of linear deleted mtDNA molecules spanning O H and O L [ 72 ]. In addition, there are increased levels of 7S DNA. The 5′-ends of these 7S DNA products are located further upstream (i.e. closer to CSB2) than what is observed in normal cells, suggesting that MGME1 is involved in processing the 5′-end of the nascent H-strand. Further studies of MGME1 and how it works together with RNASEH1 to process nascent replication products will be important.
Separation mtDNA
During DNA replication, the parental molecule remains intact, which poses a steric problem for the moving replication machinery. Topoisomerases belonging to the type 1 family can relieve torsional strain formed in this way, by allowing one of the strands to pass through the other. In mammalian mitochondria, TOP1MT a type IB enzyme can act as a DNA “swivel”, working together with the mitochondrial replisome [ 73 ]. Knockout of the Top1mt gene in mouse generates viable offspring that shows altered mtDNA supercoiling [ 74 , 75 ].
In other systems, replication of intact, circular DNA generates daughter molecules linked together as catenanes , i.e. mechanically interlocked, but not yet completely finished DNA circles. Therefore, replication of circular genomes requires decatenation to generate complete daughter molecules separation ( Figure 3 ). The existence of catenanes in mitochondria was reported already in 1967 by Vinograd and co-workers, who identified mtDNA molecules linked together by X-type brances, which they suggested were formed during completion of mtDNA replication [ 76 ]. Recently, it was demonstrated that these X-type structures are hemicatenanes, i.e. double-stranded DNA molecules linked together via a single-stranded linkage [ 77 ]. A mitochondrial isoform of Topoisomerase 3α (Top3α) is required to resolve the hemicatenane structure ( Figure 3 ), inasmuch as loss of Top3α causes decrease in mtDNA and the formation of large, catenated mtDNA networks. Patient mutations that decrease Top3α activity cause symptoms similar to those caused by mutations in other mitochondrial replication factors, including muscle-restricted mtDNA deletions and chronic progressive external ophthalmoplegia [ 77 ]. Interestingly, the hemicatenanes holding these mtDNA networks together are located to the O H -region, suggesting that these structures are formed during the completion of mtDNA replication. Even if the exact mechanisms remain unclear, previous theoretical work that has postulated ways by which hemicatenanes can be formed during replication of circular DNA molecules [ 78 ]. Further work is required to understand how mtDNA replication is terminated and hemicatenanes are formed.

After mtDNA replication, the new daughter molecules are mechanically linked via a hemicatenane structure, which requires Top3α to be resolved.
Even if Top3α is required for separation of newly replicated mtDNA, additional proteins are probably also needed. There is a nuclear isoform of Top3α that functions together with three other proteins; the helicase BLM and the OB-fold proteins RMI1 and RMI2. Together, these proteins form the BTR complex, which acts to dissolve double Holliday junctions, and Top3α requires the other subunits to exert full topoisomerase activity [ 79 ]. However, since neither BLM, RMI1, or RMI2 have mitochondrial isoforms, other proteins may partner with Top3α in mitochondria to regulate and/or stimulate its activity [ 77 ].
Nucleoid replication
mtDNA is not a naked molecule, but packaged into large nucleoprotein complexes, nucleoids [ 80 ], which can be visualized by various fluorescent microscopy approaches [ 81 ]. Studies have revealed that nucleoids have an average size of ∼100 nm in diameter [ 82 , 83 ] and in most cases there is a single mtDNA molecule per nucleoid [ 82 ]. The major structural protein component of the nucleoid is TFAM, which is present at a ratio of 1 subunit per 16–17 bp of mtDNA. TFAM is a member of the high mobility group (HMG) box domain family and it binds DNA without sequence specificity [ 84 ]. TFAM is also an essential component of the mitochondrial transcription machinery [ 85 ]. During transcription initiation, the protein binds upstream of the transcription start site and induces a sharp bend into DNA [ 86–88 ]. Nucleoid-like particles can be reconstituted by simply mixing TFAM and mtDNA, implying that TFAM on its own can fully compact mtDNA [ 89–91 ]. TFAM has two DNA binding sites, and appears to compact mtDNA by cross-strand binding and loop formation. In addition, TFAM binds DNA in a cooperative manner, forming protein-patches on mtDNA [ 90–92 ].
That TFAM acts as an epigenetic regulator of mtDNA replication is a tantalizing possibility. Super-resolution microscopy has revealed different forms of nucleoids [ 91 ]. Perhaps, the more compact nucleoids represent a mtDNA storage form, whereas the larger forms are involved in active replication and/or transcription. Nucleoids involved in active DNA replication have been localized to contact points between the endoplasmic reticulum (ER) and mitochondria. At these sites, mitochondrial division takes place, leading to the idea that contacts between the endoplasmic reticulum and mitochondria can coordinate mtDNA synthesis with division to ensure even distribution of newly replicated nucleoids within the mitochondrial network [ 93 ].
In vitro , small changes in the TFAM to DNA ratio can have dramatic consequences. At physiological ratios, there are large variations in mtDNA compaction, fully compacted nucleoids and naked DNA can be observed simultaneously. Under these conditions, a small increase in TFAM concentrations can dramatically increase the number of full compacted mtDNA molecules. [ 89 , 90 ]. This model may explain why TFAM levels in vivo remain roughly proportional to mtDNA levels, and suggests that relatively small changes in TFAM concentrations can have strong effects on both gene expression and mtDNA replication. In support of this notion, longer patches of TFAM prevents DNA unwinding and as a consequence, the mtDNA replication and transcription machineries cannot progress [ 90 ]. TFAM may therefore function as an epigenetic regulator, which controls the number of mtDNA molecules available for active transcription and/or mtDNA replication.
Concluding remarks
A detailed understanding of mtDNA replication is not only important from a basic science point of view, but may also explain the formation of deletions and point mutations associated with human disease and aging. A detailed knowledge of these process may pave the way for development of new therapeutic strategies that can be of use in mitochondrial medicine.
- Mammalian mtDNA is replicated by proteins distinct from those used for nuclear DNA replication.
- According to the strand displacement model, replication is initiated from two distinct origins, OH and OL.
- Transcripts initiated at LSP provide the primer from which POLγ can initiate DNA synthesis at OH.
- O L forms a stem–loop structure and POLRMT initiates primer synthesis from the single-stranded loop region.
- The role of the mitochondrial D-loop is not understood.
- RNASEH1 and MGME1 play important roles in primer removal, but the details of this process are not fully understood.
- Top3α is required to resolve hemicatenane structures formed between new mtDNA molecules at the end of replication.
- mtDNA is not a naked molecule, but packaged into nucleoprotein complexes, nucleoids.
- Mitochondrial division is linked to active mtDNA synthesis.
Acknowledgments
I am grateful to Dr Jay P. Uhler who prepared the illustrations.
Abbreviations
Competing interests.
The author declares that there are no competing interests associated with the manuscript.
This work was supported by Swedish Research Council (2013-3621); Swedish Cancer Foundation (CAN2016/816); European Research Council (DELMIT); the IngaBritt and Arne Lundberg Foundation; and the Knut and Alice Wallenberg Foundation.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
DNA replication articles from across Nature Portfolio
DNA replication is the biological process by which an exact copy of a deoxyribonucleic acid (DNA) molecule is created and it is the basis for biological inheritance. Each of the two strands of the DNA molecule acts as a template for the synthesis of a complementary strand.
Related Subjects
- DNA synthesis
- Fragile sites
- Origin firing
- Origin selection
- Stalled forks
- Translesion synthesis
Latest Research and Reviews

RECQL4 is not critical for firing of human DNA replication origins
- Laura Padayachy
- Sotirios G. Ntallis
- Thanos D. Halazonetis

FANCJ promotes PARP1 activity during DNA replication that is essential in BRCA1 deficient cells
Here the authors show that PARPi efficacy along with the fitness of BRCA1 deficient cells relies on FANCJ, which maintains S-phase PARP1 activity by preventing its sequestration with MSH2 on G-quadruplexes.
- Nathan MacGilvary
- Sharon B. Cantor

Transcription–replication conflicts underlie sensitivity to PARP inhibitors
Poly(ADP-ribose) polymerase 1 (PARP1) functions together with TIMELESS and TIPIN to protect the replisome in early S phase from transcription–replication conflicts, and inhibiting PARP1 enzymatic activity may suffice for treatment efficacy in homologous recombination-deficient settings.
- Michalis Petropoulos
- Angeliki Karamichali

A mechanistic model of primer synthesis from catalytic structures of DNA polymerase α–primase
The DNA polymerase α–primase complex undergoes dramatic configurational rearrangements to synthesize chimeric RNA-DNA primers across two separate active sites while maintaining simultaneous interactions at opposite ends of the primer–template duplex.
- Elwood A. Mullins
- Lauren E. Salay
- Brandt F. Eichman

ZNF827 is a single-stranded DNA binding protein that regulates the ATR-CHK1 DNA damage response pathway
Here, the authors characterise the zinc finger protein ZNF827 as a single stranded DNA binding protein that accumulates at stalled replication forks to activate the ATR-CHK1 pathway and engage homologous-recombination mediated DNA repair.
- Sile F. Yang
- Christopher B. Nelson
- Hilda A. Pickett

Parental histone transfer caught at the replication fork
Structures of the yeast replisome associated with the FACT complex and an evicted histone hexamer offer insights into the mechanism of replication-coupled histone recycling for maintaining epigenetic inheritance.
- Ningning Li
- Yuanliang Zhai
News and Comment
A leap for directed evolution.
- Rita Strack

Targeting aberrant splicing
Bland et al. show that cancer types with heterozygous somatic hotspot mutations in the spliceosome component SF3B1 are vulnerable to PARP inhibition, which causes a defective response to replication stress.
Myosin VI assists in fork protection
Shi et al. show the role of myosin VI in the protection of stalled replication forks during replication stress.
- Paulina Strzyz

Unveiling the toxicity of single-stranded DNA gaps through a yeast model
A study on a yeast model explores how ssDNA gaps induce cell death and genomic instability, implicating Rad9 and Rad51 in gap repair and protection. Gaps forming secondary structures trigger chromosome fragility, deletions, rearrangements, or cell death pathways, showing how gaps are a vulnerability in cancer cells with opportunity for selective targeting.
- Jenna M. Whalen

Transient chromatin compaction in fork restart
The compact state of chromatin induced by the methylation of lysine 9 on histone H3 has long been implicated in a heritable state of transcriptional repression. A study now shows that transient deposition of H3K9me3 helps to stabilize stalled DNA replication forks, while its reversal enables accurate fork restart.
- Susan M. Gasser

Human primase hangs on the primer–template and Polα to facilitate primer termination
We determined the structure of the Polα–primase complex trapped in a DNA elongation state. Cryo-electron microscopy showed that primase has a role in facilitating the timely termination of primer DNA elongation by Polα by hanging on the primer–template complex.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies


- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
7.8: Case Study Conclusion: Genes and Chapter Summary
- Last updated
- Save as PDF
- Page ID 17047

- Suzanne Wakim & Mandeep Grewal
- Butte College
Case Study Conclusion: Genetic Similarities and Differences
Humans are much more genetically similar to each other than they are different. Any two people on Earth are 99.9% genetically identical to each other. But the mere 0.1% that is different can be very important, as in the case of bone marrow donation to treat diseases such as leukemia. These variations are passed on in a family with sexual reproduction. A good match must exist between a bone marrow donor and recipient in genes that encode for human leukocyte antigen (HLA) proteins. If a patient receives a bone marrow transplant from a donor that has different types of HLAs than the patient does, antibodies in their immune system will identify the antigens as “nonself” and will launch an attack on the transplanted cells. Also, since bone marrow produces immune cells, antibodies in the transplanted tissue can actually attack the patient’s own cells through the same mechanism.

As you have also learned, a good HLA match is often difficult to find, even between full siblings. This is due to the genetic variations within gametes of a single person due to crossing over and random assortment. The variations are multiplied when two unique gametes fertilize. Kim has to find his match outside of his family. Every year, about 14,000 people in the United States must try to find a compatible donor from a bone marrow registry. These registries store information on HLA type from potential donors, like the woman shown above. She is swabbing her cheeks for a DNA match. It can take months to years to find a compatible match — if one is found at all.
In the meantime, Kim has to stop the production of abnormal WBCs with chemotherapy. Chemotherapy is the treatment of cancer with drugs ("anticancer drugs") that can destroy cancer cells. In current usage, the term "chemotherapy" usually refers to cytotoxic drugs which affect rapidly dividing cells in general, in contrast with targeted therapy (see below). Chemotherapy drugs interfere with cell division in various possible ways, e.g. with the duplication of DNA or the separation of newly formed chromosomes. Chemotherapy has the potential to harm healthy tissue, especially those tissues that have a high replacement rate (e.g. intestinal lining). Due to these side effects, patients may lose their hair follicles, Digestive system lining, and taste buds. These cells usually repair themselves after chemotherapy. Because some drugs work better together than alone, two or more drugs are often given at the same time. This is called "combination chemotherapy"; most chemotherapy regimens are given in a combination.
Chapter Summary
In this chapter, you learned about human sexual and asexual reproduction.
- The cell cycle is a repeating series of events that include growth, DNA synthesis, and cell division. It is more complicated in eukaryotic than prokaryotic cells.
- Except when a eukaryotic cell divides, its nuclear DNA exists as a grainy material called chromatin. After DNA replicates and the cell is about to divide, the DNA condenses and coils into the X-shaped form of a chromosome. Each replicated chromosome consists of two sister chromatids, which are joined together at a centromere.
- During mitosis, sister chromatids separate from each other and move to opposite poles of the cell. This happens in four phases, called prophase, metaphase, anaphase, and telophase.
- The cell cycle is controlled mainly by regulatory proteins that signal the cell to either start or delay the next phase of the cycle at key checkpoints.
- Cancer is a disease that occurs when the cell cycle is no longer regulated, for example, because the cell's DNA has become damaged. Cancerous cells grow out of control and may form a mass of abnormal cells called a tumor.
- In sexual reproduction, two parents produce gametes that unite in the process of fertilization to form a single-celled zygote. Gametes are haploid cells with only one of each pair of homologous chromosomes, and the zygote is a diploid cell with two of each pair of chromosomes.
- Meiosis is the type of cell division that produces four haploid daughter cells that may become gametes. Meiosis occurs in two stages, called meiosis I and meiosis II, each of which occurs in four phases (prophase, metaphase, anaphase, and telophase).
- Meiosis is followed by gametogenesis, the process in which the haploid daughter cells change into mature gametes. Males produce gametes called sperm in a process known as spermatogenesis, and females produce gametes called eggs in the process known as oogenesis.
- Sexual reproduction produces offspring that are genetically unique. Crossing-over, independent assortment, and the random union of gametes work together to result in an amazing amount of potential genetic variation.
- Sexual reproduction has the potential to produce tremendous genetic variation in offspring.
- During prophase I, the homologous chromosomes condense and become visible as the x shape we know, pair up to form a tetrad, and exchange genetic material by crossing over.
- In metaphase I, the tetrads line themselves up at the metaphase plate and homologous pairs orient themselves randomly.
- This variation is due to independent assortment and crossing-over during meiosis, and random union of gametes during fertilization.
- The goal of mitosis is to produce a new cell that is identical to the parent cell.
- The goal of meiosis is to produce gametes that have half the DNA of the parent cell.
- When chromosomes do not divide equally among gametes, the damaged gametes produce. This process is called nondisjunction.
- Trisomy is a state where humans have an extra autosome; they have three of a particular chromosome instead of two.
- The most common trisomy in viable births is Trisomy 21 (Down Syndrome) due to nondisjunction.
Chapter Summary Review
- What are cyclin-dependent kinases? What is their role?
- What are cell cycle checkpoints?
- What is interphase?
- Summarize each phase of the cell cycle.
- Describe the structure of a chromosome in the prophase of mitosis.
- What is cytokinesis and when does it occur?
- What is centromere?
- Describe the main steps of mitosis.
- Cells go through a series of events that include growth, DNA synthesis, and cell division. Why are these events best represented by a cycle diagram?
- Explain how the cell cycle is regulated.
- Define and explain random assortment and random fertilization.
- Why is DNA replication essential to the cell cycle?
- True or False. When a eukaryotic cell divides, the nucleus divides first in the process of mitosis.
- What happens during mitosis?
- What is meiosis?
- What is diploid? How many chromosomes are in a diploid human cell?
- What is a zygote? How does the zygote form the organism?
- What is the result of crossing-over?
- How many cell divisions occur during meiosis?
- Why are you genetically distinct?
- Describe the steps of Meiosis I and Meiosis II.
- Describe nondisjunction. List and explain some of the chromosome disorders.
- Compare and contrast mitosis and meiosis.
Explore More
Attributions.
- USARC officer by Timothy Hale, public domain via Wikimedia Commons
- Text adapted from Human Biology by CK-12 licensed CC BY-NC 3.0

- Previous Article
- Next Article
Cover Image
Introduction, mtdna replication factors, the mode of mtdna replication, initiation of mtdna replication at o h, termination of mtdna replication, separation mtdna, nucleoid replication, concluding remarks, competing interests, abbreviations, mitochondrial dna replication in mammalian cells: overview of the pathway.
- Split-Screen
- Article contents
- Figures & tables
- Supplementary Data
- Peer Review
- Open the PDF for in another window
- Cite Icon Cite
- Get Permissions
Caterina Garone , Michal Minczuk , Maria Falkenberg; Mitochondrial DNA replication in mammalian cells: overview of the pathway. Essays Biochem 20 July 2018; 62 (3): 287–296. doi: https://doi.org/10.1042/EBC20170100
Download citation file:
- Ris (Zotero)
- Reference Manager
Mammalian mitochondria contain multiple copies of a circular, double-stranded DNA genome and a dedicated DNA replication machinery is required for its maintenance. Many disease-causing mutations affect mitochondrial replication factors and a detailed understanding of the replication process may help to explain the pathogenic mechanisms underlying a number of mitochondrial diseases. We here give a brief overview of DNA replication in mammalian mitochondria, describing our current understanding of this process and some unanswered questions remaining.
Mitochondrial DNA (mtDNA) is a double-stranded molecule of 16.6 kb ( Figure 1 , lower panel). The two strands of mtDNA differ in their base composition, with one being rich in guanines, making it possible to separate a heavy (H) and a light (L) strand by density centrifugation in alkaline CsCl 2 gradients [ 1 ]. The mtDNA contains one longer noncoding region (NCR) also referred to as the control region. In the NCR, there are promoters for polycistronic transcription, one for each mtDNA strand; the light strand promoter (LSP) and the heavy strand promoter (HSP). The NCR also harbors the origin for H-strand DNA replication (O H ). A second origin for L-strand DNA replication (O L ) is located outside the NCR, within a tRNA cluster approximately 11,000 bp downstream of O H .
Map of human mtDNA

The genome encodes for 13 mRNA (green), 22 tRNA (violet), and 2 rRNA (pale blue) molecules. There is also a major noncoding region (NCR), which is shown enlarged at the top. The major NCR contains the heavy strand promoter (HSP), the light strand promoter (LSP), three conserved sequence boxes (CSB1-3, orange), the H-strand origin of replication (O H ), and the termination-associated sequence (TAS, yellow). The triple-stranded displacement-loop (D-loop) structure is formed by premature termination of nascent H-strand DNA synthesis at TAS. The short H-strand replication product formed in this manner is termed 7S DNA. A minor NCR, located approximately 11,000 bp downstream of O H , contains the L-strand origin of replication (O L ).
Mammalian mtDNA is replicated by proteins distinct from those used for nuclear DNA replication and many are related to replication factors identified in bacteriophages [ 2 ]. DNA polymerase γ (POLγ) is the replicative polymerase in mitochondria. In human cells, POLγ is a heterotrimer with one catalytic subunit (POLγA) and two accessory subunits (POLγB) [ 3–5 ]. Mouse knockouts for POLγA and POLγB have revealed that both factors are essential for embryonic development [ 6 , 7 ]. At least four additional polymerases (PrimPol, DNA polymerase β, DNA polymerase θ, and DNA polymerase ζ) have been reported to play a role mitochondria [ 8–11 ]. These polymerases are not essential for mtDNA maintenance and none of them can substitute for POLγ. Most likely they are involved in mtDNA repair, but the exact function of these additional polymerases in mtDNA maintenance needs to be further elucidated (reviewed in [ 12 ]).
POLγA belongs to the family A DNA polymerases and contains a 3′–5′ exonuclease domain that acts to proofread the newly synthesized DNA strand [ 3 ]. POLγ is a highly accurate DNA polymerase with a frequency of misincorporation lower than 1 × 10 −6 [ 13 ]. The accessory POLγB subunit enhances interactions with the DNA template and increases both the catalytic activity and the processivity of POLγA [ 14–16 ]. POLγ cannot use double-stranded DNA as a template and a DNA helicase is therefore required at the mitochondrial replication fork [ 17 ]. The DNA helicase TWINKLE is homologous to the T7 phage gene 4 protein [ 18 ] and during mtDNA replication, TWINKLE travels in front of POLγ, unwinding the double-stranded DNA template. TWINKLE forms a hexamer and requires a fork structure (a single-stranded 5′-DNA loading site and a short 3′-tail) to load and initiate unwinding [ 18–20 ]. Mitochondrial single-stranded DNA-binding protein (mtSSB) binds to the formed ssDNA, protects it against nucleases, and prevents secondary structure formation [ 21 , 22 ]. mtSSB enhances mtDNA synthesis by stimulating TWINKLE’s helicase activity as well as increasing the processivity of POLγ [ 17 , 19 , 23 ].
A model for mtDNA replication was presented already in 1972 by Vinograd and co-workers ( Figure 2 ) [ 24 ]. According their strand displacement model, DNA synthesis is continuous on both the H- and L-strand [ 25 ]. There is a dedicated origin for each strand, O H and O L . First, replication is initiated at O H and DNA synthesis then proceeds to produce a new H-strand. During the initial phase, there is no simultaneous L-strand synthesis and mtSSB covers the displaced, parental H-strand [ 26 ]. By binding to single-stranded DNA, mtSSB prevents the mitochondrial RNA polymerase (POLRMT) from initiating random RNA synthesis on the displaced strand [ 27 ]. When the replication fork has progressed about two-thirds of the genome, it passes the second origin of replication, O L . When exposed in its single-stranded conformation, the parental H-strand at O L folds into a stem–loop structure [ 28 ]. The stem efficiently blocks mtSSB from binding and a short stretch of single-stranded DNA in the loop region therefore remains accessible, allowing POLRMT to initiate RNA synthesis [ 26 , 29 ]. POLRMT is not processive on a single-stranded DNA templates [ 27 ]. Already after about 25 nt, it is replaced by POLγ and L-strand DNA synthesis is initiated [ 30 ]. From this point, H- and L-strand synthesis proceeds continuously until the two strands have reached full circle. Replication of the two strands is linked, since H-strand synthesis is required for initiation of L-strand synthesis. The structure and the sequence requirement for mammalian O L has been studied both in vivo and in vitro , demonstrating that a functional human O L must include a stable double-stranded stem region with pyrimidine-rich template strand and a single-stranded loop of at least 10 nt [ 31 ].
Replication of the human mitochondrial genome

Mitochondrial DNA replication is initiated at O H and proceeds unidirectionally to produce the full-length nascent H-strand. mtSSB binds and protects the exposed, parental H-strand. When the replisome passes O L , a stem–loop structure is formed that blocks mtSSB binding, presenting a single-stranded loop-region from which POLRMT can initiate primer synthesis. The transition to L-strand DNA synthesis takes place after about 25 nt, when POLγ replaces POLRMT at the 3′-end of the primer. Synthesis of the two strands proceeds in a continuous manner until two full, double-stranded DNA molecules have been formed.
It should be noted that some aspects of the strand-displacement model have been questioned. For instance, studies have suggested that processed RNA molecules hybridize to the single-stranded H-strand and function as a provisional lagging strand, which is replaced by DNA during later stages of mtDNA replication [ 32 ]. This so-called RITOLS model implicates that processed transcripts are successively hybridized to the paternal H-strand as the replication fork advances, but the enzymatic machinery required for this process has not been identified [ 33 ]. Arguing against the RITOLS model, single-stranded DNA binding proteins are used to stabilize single-stranded DNA intermediates during DNA replication in all three major branches of life. In mitochondria, there are at least 500 mtSSB tetramers available per mtDNA molecule. Since each tetramer binds 59 nt, the levels of mtSSB are sufficient to cover the entire parental H-strand during mtDNA synthesis [ 26 , 34 ]. In addition, strand-specific chromatin immunoprecipitation has revealed that mtSSB exclusively covers the parental H-strand during mtDNA replication in vivo . The occupancy profile displays a distinct pattern, with the highest levels of mtSSB close to OriH, followed by a gradual decline toward OriL. The pattern is thus as would be predicted if mtSSB functions to stabilize the single-stranded, paternal H-strand during strand-displacement DNA replication [ 26 ]. Yet another problem for the RITOLS model is the presence of RNASEH1 in mitochondria. This enzyme efficiently removes RNA–DNA hybrids, an activity that is difficult to reconcile with processed RNA molecules stably binding to long stretches of single-stranded DNA during mtDNA replication [ 35 ].
Finally, there have been reports suggesting that under certain conditions, strand-coupled replication may function as a backup replication mode in mammalian mitochondria [ 36 , 37 ]. The molecular mechanisms underlying this type of replication have not been elucidated.
Curiously, not all replication events initiated at O H continue to full circle. Instead, 95% are terminated already after about 650 nt at the termination associated sequences (TAS) [ 38 , 39 ]. The short DNA fragment formed in this way, 7S DNA, remains bound to the parental L-strand, while the parental H-strand is displaced ( Figure 1 , top panel). As a result, a triple-stranded displacement loop structure, a D-loop, is formed. The functional importance of the D-loop structure is unclear and how replication is terminated at TAS is also not known [ 40 , 41 ]. It appears however that termination at TAS is a regulated event, providing a switch between abortive and genome length mtDNA replication [ 42 ]. In support of this notion, in vivo occupation analysis revealed that POLγ under normal conditions stalls at the 3′-end of the D-loop, whereas TWINKLE occupancy is low in this region. When mtDNA is depleted, the situation changes and TWINKLE occupancy increases and at the same time 7S DNA levels are decreased. These data have been interpreted as evidence for TWINKLE reloading in response to increased demand for mtDNA replication [ 42 ]. Binding of the helicase to the 3′-end of 7S DNA would allow the stalled POLγ to continue replication of 7S DNA to full circle. The model receives support from mouse genetic experiments, demonstrating that TWINKLE is important for mtDNA copy number control. Increased or decreased levels of TWINKLE correlate nicely with mtDNA levels [ 43–46 ]. It is thus possible that mtDNA replication is regulated at the level of pretermination rather than initiation. The switch may fine-tune the mtDNA copy number in response to cellular demands.
Interestingly, two closely related 15 nt and evolutionary conserved palindromic sequence motifs (ATGN 9 CAT) are located on each side of the D-loop region. One motif is located just upstream of the 5′-end of the 7S DNA, where it forms a part of conserved sequence box 1, CSB1. The second motif, core-TAS, is located within the TAS region, just downstream of the 3′-end of 7S DNA ( Figure 1 , top panel) [ 42 ]. The physiological role of these motifs remains unclear, but sequence-specific DNA binding proteins often recognize and bind palindromic sequences. In support of this notion, there are published in organello footprints located to the TAS region [ 47 ], but despite substantial efforts in different laboratories, a TAS-binding protein has so far not been identified. It is possible that the proteins binding to CSB1, core-TAS, and other regions within TAS are difficult to purify by traditional methods. Perhaps the missing protein is membrane bound and difficult to retain in solution during chromatography. Alternatively, binding could be a regulated event, requiring precise redox conditions or nucleotide concentrations. Finally, it cannot be excluded that secondary structures in mtDNA may play a role, e.g. stem–loops or G-quadruplexes, which could also contribute to the observed in vivo DNA footprints.
We know that POLRMT forms the primers necessary to initiate H-strand synthesis O H [ 48–51 ]. Transcripts initiated at LSP provide RNA 3′-ends from which POLγ can initiate DNA synthesis. In human mitochondria, there are multiple transitions points (RNA-to-DNA transitions) located downstream of LSP, clustering around two conserved sequence motifs, CSB3 and CSB2 ( Figure 1 , top panel) [ 52–54 ]. These conserved sequence elements are guanine-rich and during transcription, a G-quadruplex structure can form between nascent RNA and the nontemplate DNA strand at CSB2. In this manner, the nascent transcript is anchored to mtDNA, forming an R-loop structure [ 30 , 55 ]. The G-quadruplex structure also causes premature transcription termination at sites roughly corresponding to RNA to DNA transition sites mapped in the CSB2-region [ 56 ]. Based on these observations, it was hypothesized that sequence-dependent transcription termination may be responsible for primer formation at O H [ 54–56 ]. The transcription elongation factor TEFM, strongly reduces transcription termination and R-loop formation at CSB2, leading to the suggestion that active TEFM may influence the ratio between primer formation and full-length, productive transcription [ 57 , 58 ]. Arguing against this idea, knockdown of TEFM in cells only has very limited effects on mtDNA copy number and mitochondrial replication intermediates [ 59 ]. In addition, there are no direct experimental evidence demonstrating that R-loop-forming, prematurely terminated transcripts can be directly used by POLγ to initiate DNA synthesis. Further experiments are clearly needed to define the precise role of R-loops and TEFM in replication initiation.
The mechanisms of DNA replication initiation at O H may resemble those previously described for initiation of DNA replication in the E. coli plasmid ColE1. In the plasmid, a transcript denoted RNAII associates with the template strand, forming an R-loop that is used to prime DNA synthesis [ 60 , 61 ]. Furthermore, the ColE1 origin of replication is situated downstream of a guanine-rich stretch that is essential for both replication initiation and R-loop formation [ 61 , 62 ]. In ColE1, the R-loop is cleaved by RNase H, before it is used to prime DNA synthesis. If the mitochondrial RNASEH1 plays a similar role in mammalian cells remains to be determined [ 63 , 64 ].
When POLγ has completed synthesis, the newly formed DNA strands are ligated by DNA ligase III [ 65 , 66 ]. To allow for efficient ligation, the 5′- and 3′-ends of the nascent DNA ends must be juxtaposed, which means that the RNA primers used to initiate mtDNA synthesis must first be removed [ 67 ]. A likely candidate for primer removal is RNASEH1, inasmuch as RNA primers are retained in the mitochondrial origin regions in mouse embryonic fibroblasts lacking Rnaseh1 and there is a loss of mtDNA in Rnaseh1 knockout mice [ 35 , 68 ].
After completing a full circle-replication, POLγ encounters the 5′-end of the nascent full-length mtDNA strand it has just produced. At this point, POLγ initiates successive cycles of polymerization and 3′–5′ exonuclease degradation at the nick [ 67 , 69 ]. This process, idling, is required for proper ligation. POLγ lacking exonuclease activity is unable to idle and instead continues DNA synthesis into the dsDNA region past the 5′-end, thereby creating a flap-structure that cannot be ligated. Failure to create ligatable DNA ends may explain why mice with exonuclease-deficient POLγ display strand-specific nicks at O H [ 67 , 70 ].
Interestingly, there is a major 5′-end of nascent DNA located approximately 100 bp further downstream of the identified RNA-to-DNA transitions sites. Historically, this site (position 191 in human mtDNA) has been seen as a part of O H , but how this 5′-end is generated is not clear [ 25 ]. Although initially identified as a start site for mtDNA replication, the free 5′-end at position 191 may be generated in other ways. For instance, the nascent H-strand may undergo considerable 5′-end processing during primer removal, removing not only the RNA primer, but also ∼100 nt of downstream DNA [ 42 ]. In this way, the site for RNA-to-DNA transition would be separated from the site of nascent H-strand ligation at the end of replication. A possible candidate for this effect is the mitochondrial genome maintenance exonuclease 1 (MGME1), a mitochondrial RecB-type exonuclease belonging to the PD-(D/E)XK nuclease superfamily [ 71 , 72 ]. In vitro analysis revealed that MGME1 cuts both ssDNA and DNA flap substrates. Human cells lacking active MGME1 display impaired ligation at O H and the formation of linear deleted mtDNA molecules spanning O H and O L [ 72 ]. In addition, there are increased levels of 7S DNA. The 5′-ends of these 7S DNA products are located further upstream (i.e. closer to CSB2) than what is observed in normal cells, suggesting that MGME1 is involved in processing the 5′-end of the nascent H-strand. Further studies of MGME1 and how it works together with RNASEH1 to process nascent replication products will be important.
During DNA replication, the parental molecule remains intact, which poses a steric problem for the moving replication machinery. Topoisomerases belonging to the type 1 family can relieve torsional strain formed in this way, by allowing one of the strands to pass through the other. In mammalian mitochondria, TOP1MT a type IB enzyme can act as a DNA “swivel”, working together with the mitochondrial replisome [ 73 ]. Knockout of the Top1mt gene in mouse generates viable offspring that shows altered mtDNA supercoiling [ 74 , 75 ].
In other systems, replication of intact, circular DNA generates daughter molecules linked together as catenanes , i.e. mechanically interlocked, but not yet completely finished DNA circles. Therefore, replication of circular genomes requires decatenation to generate complete daughter molecules separation ( Figure 3 ). The existence of catenanes in mitochondria was reported already in 1967 by Vinograd and co-workers, who identified mtDNA molecules linked together by X-type brances, which they suggested were formed during completion of mtDNA replication [ 76 ]. Recently, it was demonstrated that these X-type structures are hemicatenanes, i.e. double-stranded DNA molecules linked together via a single-stranded linkage [ 77 ]. A mitochondrial isoform of Topoisomerase 3α (Top3α) is required to resolve the hemicatenane structure ( Figure 3 ), inasmuch as loss of Top3α causes decrease in mtDNA and the formation of large, catenated mtDNA networks. Patient mutations that decrease Top3α activity cause symptoms similar to those caused by mutations in other mitochondrial replication factors, including muscle-restricted mtDNA deletions and chronic progressive external ophthalmoplegia [ 77 ]. Interestingly, the hemicatenanes holding these mtDNA networks together are located to the O H -region, suggesting that these structures are formed during the completion of mtDNA replication. Even if the exact mechanisms remain unclear, previous theoretical work that has postulated ways by which hemicatenanes can be formed during replication of circular DNA molecules [ 78 ]. Further work is required to understand how mtDNA replication is terminated and hemicatenanes are formed.
Separation and segregation of the human mitochondrial genome

After mtDNA replication, the new daughter molecules are mechanically linked via a hemicatenane structure, which requires Top3α to be resolved.
Even if Top3α is required for separation of newly replicated mtDNA, additional proteins are probably also needed. There is a nuclear isoform of Top3α that functions together with three other proteins; the helicase BLM and the OB-fold proteins RMI1 and RMI2. Together, these proteins form the BTR complex, which acts to dissolve double Holliday junctions, and Top3α requires the other subunits to exert full topoisomerase activity [ 79 ]. However, since neither BLM, RMI1, or RMI2 have mitochondrial isoforms, other proteins may partner with Top3α in mitochondria to regulate and/or stimulate its activity [ 77 ].
mtDNA is not a naked molecule, but packaged into large nucleoprotein complexes, nucleoids [ 80 ], which can be visualized by various fluorescent microscopy approaches [ 81 ]. Studies have revealed that nucleoids have an average size of ∼100 nm in diameter [ 82 , 83 ] and in most cases there is a single mtDNA molecule per nucleoid [ 82 ]. The major structural protein component of the nucleoid is TFAM, which is present at a ratio of 1 subunit per 16–17 bp of mtDNA. TFAM is a member of the high mobility group (HMG) box domain family and it binds DNA without sequence specificity [ 84 ]. TFAM is also an essential component of the mitochondrial transcription machinery [ 85 ]. During transcription initiation, the protein binds upstream of the transcription start site and induces a sharp bend into DNA [ 86–88 ]. Nucleoid-like particles can be reconstituted by simply mixing TFAM and mtDNA, implying that TFAM on its own can fully compact mtDNA [ 89–91 ]. TFAM has two DNA binding sites, and appears to compact mtDNA by cross-strand binding and loop formation. In addition, TFAM binds DNA in a cooperative manner, forming protein-patches on mtDNA [ 90–92 ].
That TFAM acts as an epigenetic regulator of mtDNA replication is a tantalizing possibility. Super-resolution microscopy has revealed different forms of nucleoids [ 91 ]. Perhaps, the more compact nucleoids represent a mtDNA storage form, whereas the larger forms are involved in active replication and/or transcription. Nucleoids involved in active DNA replication have been localized to contact points between the endoplasmic reticulum (ER) and mitochondria. At these sites, mitochondrial division takes place, leading to the idea that contacts between the endoplasmic reticulum and mitochondria can coordinate mtDNA synthesis with division to ensure even distribution of newly replicated nucleoids within the mitochondrial network [ 93 ].
In vitro , small changes in the TFAM to DNA ratio can have dramatic consequences. At physiological ratios, there are large variations in mtDNA compaction, fully compacted nucleoids and naked DNA can be observed simultaneously. Under these conditions, a small increase in TFAM concentrations can dramatically increase the number of full compacted mtDNA molecules. [ 89 , 90 ]. This model may explain why TFAM levels in vivo remain roughly proportional to mtDNA levels, and suggests that relatively small changes in TFAM concentrations can have strong effects on both gene expression and mtDNA replication. In support of this notion, longer patches of TFAM prevents DNA unwinding and as a consequence, the mtDNA replication and transcription machineries cannot progress [ 90 ]. TFAM may therefore function as an epigenetic regulator, which controls the number of mtDNA molecules available for active transcription and/or mtDNA replication.
A detailed understanding of mtDNA replication is not only important from a basic science point of view, but may also explain the formation of deletions and point mutations associated with human disease and aging. A detailed knowledge of these process may pave the way for development of new therapeutic strategies that can be of use in mitochondrial medicine.
Mammalian mtDNA is replicated by proteins distinct from those used for nuclear DNA replication.
According to the strand displacement model, replication is initiated from two distinct origins, OH and OL.
Transcripts initiated at LSP provide the primer from which POLγ can initiate DNA synthesis at OH.
O L forms a stem–loop structure and POLRMT initiates primer synthesis from the single-stranded loop region.
The role of the mitochondrial D-loop is not understood.
RNASEH1 and MGME1 play important roles in primer removal, but the details of this process are not fully understood.
Top3α is required to resolve hemicatenane structures formed between new mtDNA molecules at the end of replication.
mtDNA is not a naked molecule, but packaged into nucleoprotein complexes, nucleoids.
Mitochondrial division is linked to active mtDNA synthesis.
I am grateful to Dr Jay P. Uhler who prepared the illustrations.
The author declares that there are no competing interests associated with the manuscript.
This work was supported by Swedish Research Council (2013-3621); Swedish Cancer Foundation (CAN2016/816); European Research Council (DELMIT); the IngaBritt and Arne Lundberg Foundation; and the Knut and Alice Wallenberg Foundation.
heavy strand promoter
light strand promoter
mitochondrial genome maintenance exonuclease 1
mitochondrial single-stranded DNA-binding protein
noncoding region
termination-associated sequence
Get Email Alerts
- Online ISSN 1744-1358
- Print ISSN 0071-1365
- Submit Your Work
- Language-editing services
- Recommend to Your Librarian
- Request a free trial
- Accessibility
- Sign up for alerts
- Sign up to our mailing list
- The Biochemist Blog
- Biochemical Society Membership
- Publishing Life Cycle
- Biochemical Society Events
- About Portland Press
- Portland Press Tel
- +44 (0)20 3880 2795
- Portland Press Company no. 02453983
- Biochemical Society Tel
- +44 (0)20 3880 2793
- Email: [email protected]
- Biochemical Society Company no. 00892796
- Registered Charity no. 253894
- VAT no. GB 523 2392 69
- Privacy and cookies
- © Copyright 2024 Portland Press
This Feature Is Available To Subscribers Only
Sign In or Create an Account
IMAGES
VIDEO
COMMENTS
ADVERTISEMENTS: In this essay we will discuss about:- 1. Definition of DNA Replication 2. Mechanism of DNA Replication 3. Evidences for Semi-Conservative DNA Replication 4. Models for Replication of Prokaryotic DNA. Essay # Definition of DNA Replication: DNA replicates by "unzipping" along the two strands, breaking the hydrogen bonds which link the pairs of nucleotides. […]
DNA replication is semiconservative, meaning that each strand in the DNA double helix acts as a template for the synthesis of a new, complementary strand. This process takes us from one starting molecule to two "daughter" molecules, with each newly formed double helix containing one new and one old strand.
which replication generates a double helix in which both strands are newly synthesized. Ergo, DNA replication is semi-conservative. DNA is synthesized by the repetitive addition of nucleotides to the 3' end of the growing polynucleotide chain DNA is synthesized by an iterative process in which nucleotides are added
DNA replication has been extremely well-studied in prokaryotes, primarily because of the small size of the genome and large number of variants available. Escherichia coli has 4.6 million base pairs in a single circular chromosome, and all of it gets replicated in approximately 42 minutes, starting from a single origin of replication and ...
Figure 9.2.1 9.2. 1: The two strands of DNA are complementary, meaning the sequence of bases in one strand can be used to create the correct sequence of bases in the other strand. Because of the complementarity of the two strands, having one strand means that it is possible to recreate the other strand.
DNA replication takes place in 5'®3' direction. This means that bases will be added from left to right direction. The template strand will guide this process by telling the new strand which base comes next, this will go on until the new strand is complete and the DNA will once again be double-stranded. ... Conclusion. In conclusion, DNA ...
Conclusion. DNA replication is a highly regulated molecular process where a single molecule of DNA is duplicated to result in two identical DNA molecules. As a semiconservative process, the double helix is broken down into two strands, where each strand serves as the template for the newly synthesized strand by matching complementary bases. ...
Dispersive replication. In the dispersive model, DNA replication results in two DNA molecules that are mixtures, or "hybrids," of parental and daughter DNA. In this model, each individual strand is a patchwork of original and new DNA. Most biologists at the time would likely have put their money on the semi-conservative model.
Key Terms. origin of replication: a particular sequence in a genome at which replication is initiated; leading strand: the template strand of the DNA double helix that is oriented so that the replication fork moves along it in the 3′ to 5′ direction; lagging strand: the strand of the template DNA double helix that is oriented so that the replication fork moves along it in a 5′ to 3′ manner
By defining DNA replication as semiconservative, the researchers made it evident that every double helix axis in the DNA structure built with the help of DNA polymerases leads to the creation of an entirely new strand that acts as complementary (Georgia Highlands College, n.d.). It should also be borne in mind that the specified characteristic ...
RNA primers are removed by exonuclease activity. Gaps are filled by DNA pol by adding dNTPs. The gap between the two DNA fragments is sealed by DNA ligase, which helps in the formation of phosphodiester bonds. Table 14.4.1 14.4. 1 summarizes the enzymes involved in prokaryotic DNA replication and the functions of each.
Introduction. DNA synthesis occurs during the S phase of the cell cycle and is ensured by the replisome, a molecular machine made of a large number of proteins acting in a coordinated manner to synthesize DNA at many genomic locations, the replication origins 1.Replication origin activation in space and time (or replication program) is set by a sequence of events, starting already at the end ...
Working with Molecular Genetics Chapter 6, DNA Replication_2, Control analogy. Imagine that 20 students are writing essays using word processors set to use black letters. They are all at different stages of completing their papers, and they are not revising or editing their essays - just writing them from start to finish.
Summary: DNA replication takes place in three major steps. Opening of the double-stranded helical structure of DNA and separation of the strands. Priming of the template strands. Assembly of the newly formed DNA segments. During the separation of DNA, the two strands uncoil at a specific site known as the origin.
The process of DNA replication plays a crucial role in providing genetic continuity from one generation to the next. Knowledge of the structure of DNA began with the discovery of nucleic acids in 1869. In 1952, an accurate model of the DNA molecule was presented, thanks to the work of Rosalind Franklin, James Watson, and Francis Crick.
To do so, DNA replicates following the process of semi-conservative replication. Two strands of DNA are obtained from one, having produced two daughter molecules that are identical to one another and to the parent molecule. This essay reviews the three stages. 487 Words. 2 Pages.
The process is quite rapid and occurs with few errors. DNA replication uses a large number of proteins and enzymes (Table 11.2.1 11.2. 1 ). One of the key players is the enzyme DNA polymerase, also known as DNA pol. In bacteria, three main types of DNA polymerases are known: DNA pol I, DNA pol II, and DNA pol III.
Essays Biochem. 2018 Jul 20; 62(3): 287-296. ... During DNA replication, the parental molecule remains intact, which poses a steric problem for the moving replication machinery. Topoisomerases belonging to the type 1 family can relieve torsional strain formed in this way, by allowing one of the strands to pass through the other. ...
Introduction. The process of DNA (Deoxyribonucleic acid) replication plays a very imperative role in providing genetic continuity from one generation to the succeeding one. Knowledge of the structure of the DNA began in 1869, with the discovery of nucleic acids. An accurate model of the DNA molecule was presented in 1952 by Rosalind Franklin ...
DNA replication is the biological process by which an exact copy of a deoxyribonucleic acid (DNA) molecule is created and it is the basis for biological inheritance. Each of the two strands of the ...
Dna Replication Essay. Since we discovered that DNA is in the nucleus in every single cell, we're curious about how exactly DNA can be replicated in a way that can keep our identity, including our characteristics. ... In conclusion, even through replication, we are still able to keep our characteristics due to the stationary and unchanging ...
Chapter Summary. In this chapter, you learned about human sexual and asexual reproduction. The cell cycle is a repeating series of events that include growth, DNA synthesis, and cell division. It is more complicated in eukaryotic than prokaryotic cells. In a eukaryotic cell, the cell cycle has two major phases: interphase and mitotic phase.
DNA replication stands as one of the fundamental biological processes crucial for cellular functioning. Recent experimental developments enable the study of replication dynamics at the single-molecule level for complete genomes, facilitating a deeper understanding of its main parameters. In these new data, replication dynamics is reported by the incorporation of an exogenous chemical, whose ...
Mitochondrial DNA (mtDNA) is a double-stranded molecule of 16.6 kb (Figure 1, lower panel).The two strands of mtDNA differ in their base composition, with one being rich in guanines, making it possible to separate a heavy (H) and a light (L) strand by density centrifugation in alkaline CsCl 2 gradients [].The mtDNA contains one longer noncoding region (NCR) also referred to as the control region.